Background
Overview
Teaching: 5 min
Exercises: 0 minQuestions
What is the Ocean Tracking Network?
How does your local telemetry network interact with OTN?
What methods of data analysis will be covered?
Objectives
Intro to OTN
The Ocean Tracking Network (OTN) supports global telemetry research by providing training, equipment, and data infrastructure to our large network of partners.
OTN and affiliated networks provide automated cross-referencing of your detection data with other tags in the system to help resolve “mystery detections” and provide detection data to taggers in other regions. OTN’s Data Managers will also extensively quality-control your submitted metadata for errors to ensure the most accurate records possible are stored in the database. OTN’s database and Data Portal website are excellent places to archive your datasets for future use and sharing with collaborators. We offer pathways to publish your datasets with OBIS, and via open data portals like ERDDAP, GeoServer etc. The data-product format returned by OTN is directly ingestible by analysis packages such as glatos and resonATe for ease of analysis. OTN offers support for the use of these packages and tools.
Learn more about OTN and our partners here https://members.oceantrack.org/. Please contact OTNDC@DAL.CA if you are interested in connecting with your regional network and learning about their affiliation with OTN.
Intended Audience
This set of workshop material is directed at OTN-reporting researchers who want more information about how to report to OTN, and what happens behind the scenes in the OTN data system.
In this walkthrough we will be looking at:
- How to report to OTN, what to report to OTN, how to access OTN data products
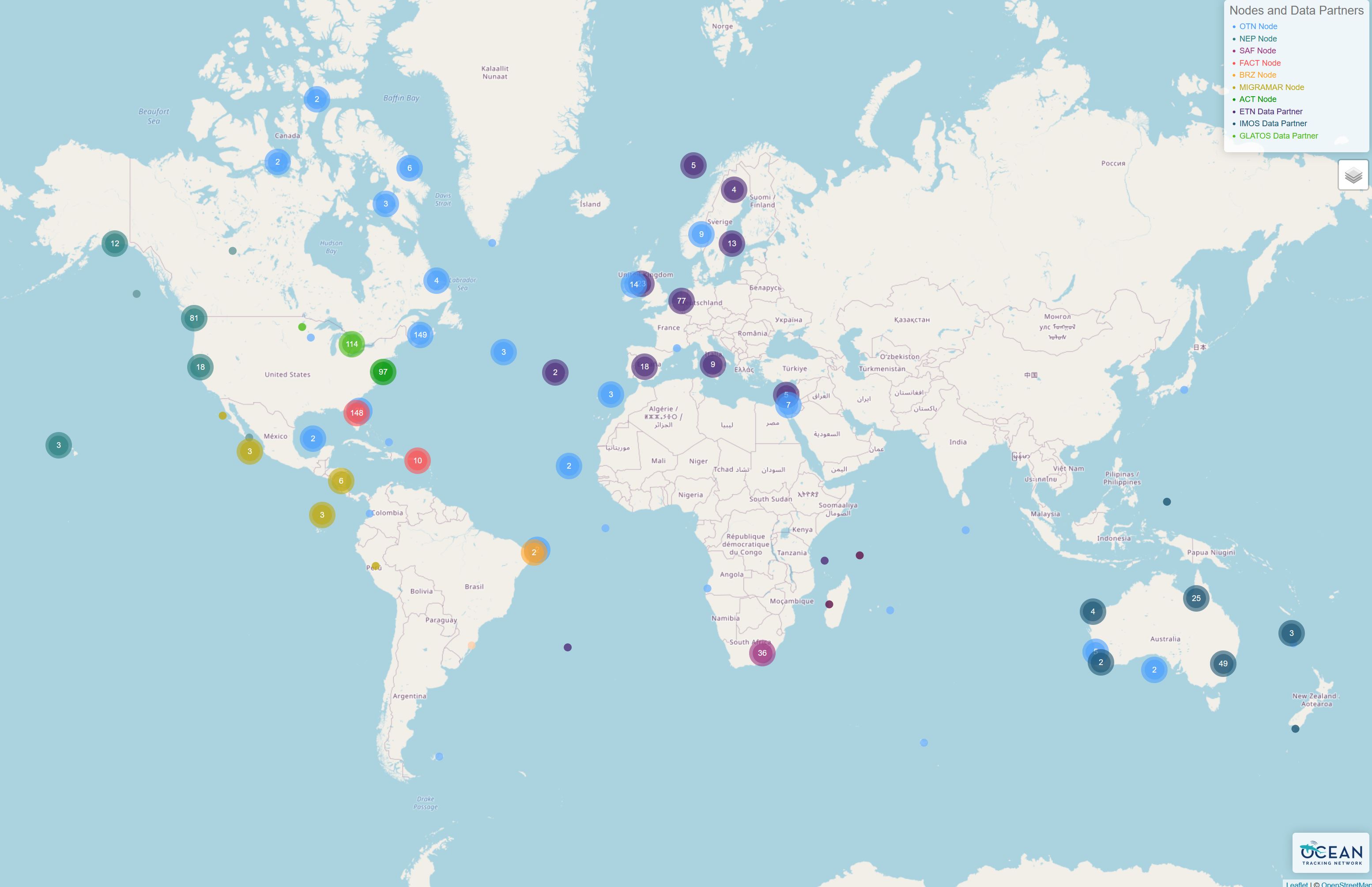
- The OTN Network of partner Nodes
- Database systems, structure and outputs
- All about OTN Data Pushes
- Other ways OTN supports the telemetry community
Key Points
OTN is a global organization.
More informatin is available on the Data Portal
Reporting to the Database
Overview
Teaching: 30 min
Exercises: 0 minQuestions
How do I report to the OTN Database?
Why should I report my data?
How do I receive my detection matches?
Objectives
Reporting Data to an OTN Node
As researchers who are part of the OTN Network, you are encouraged to register your projects and report your data and metadata in a timely manner to your Data Manager. This will benefit all researchers in the region through the database’s detection-matching system.
This presentation ONC and OTN: a Collaboration will cover some of the following topics.
You are encouraged to read the OTN FAQs Page for more information.
How to register with the OTN Database
In order to register a project with OTN, we require 3 metadata types:
- project metadata
- instrument deployment metadata
- tagging metadata
See the templates here. OTNDC@DAL.CA is the best contact for assistance
What is the benefit of registering with the OTN Database?
OTN and affiliated networks provide automated cross-referencing of your detection data with other tags in the system to help resolve “mystery detections” and provide detection data to taggers in other regions. OTN’s Data Manager will also extensively quality control your submitted metadata for errors to ensure the most accurate records possible are stored in the database. OTN’s database and Data Portal website are excellent places to archive your datasets for future use and sharing with collaborators. We offer pathways to publish your datasets with OBIS, and via open data portals like ERDDAP, GeoServer etc. The data-product format returned by OTN is directly ingestible by analysis packages such as glatos and resonATe for ease of analysis. OTN offers support for the use of these packages and tools.
What is the Data Portal?
OTN’s Data Portal website is similar to DropBox or another file repository service. While there are helpful links and tools to explore, this site is mainly used to hold private repository folders for each project. In your project folder, you can add files which can be viewed ONLY by anyone who has been given access. These folders are also where the Data Manager will upload your Detection Extracts when they are ready.
OTN’s database is built on PostgreSQL/PostGIS and is hosted on OTN hardware at Dalhousie University. Many partner Nodes are hosted at other locations. Users do not have direct write access to the database: the files posted in your Data Portal folder will be downloaded, quality controlled and loaded into the database by a Data Manager.
Receiving Detection Matches
As researchers who have already submitted data and metadata to the OTN Database, you will receive detection-matches for the tags detected on your array and the tags you have release. These are in standard formats call “Detection Extracts” and are provided to you several times a year during a “data push”.
What are Detection Extract data products?
OTN and all of its partner Nodes create Detection Extracts on a semi-regular basis (approximately every 4 months) following a cross-Node coordinated detection matching event known as a Data Push. These Detection Extract files contain only the detections for the year corresponding to the suffix on the file name. See the detailed detection extract documentation for more information.
Key Points
Metadata templates are used to report records
OTN matches data and metadata across numerous geographic areas
Detection extracts are returned to researchers after data pushes
Introduction to Nodes
Overview
Teaching: 30 min
Exercises: 0 minQuestions
What is an OTN-style Database Node?
Objectives
Understand the relationship between OTN and its Nodes.
What is a Node?
OTN partners with regional acoustic telemetry networks around the world to enable detection-matching across our communities. An OTN Node is an exact copy of OTN’s acoustic telemetry database structure, which allows for direct cross-referencing between the data holdings of each regional telemetry sharing community. The list of OTN Nodes is available at https://members.oceantrack.org. Data only needs to be reported to one Node in order for tags/detections to be matched across all.
How does a Node benefit its users?
OTN and affiliated networks provide automated cross-referencing of your detection data with other tags in the system to help resolve “mystery detections” and provide detection data to taggers in other regions. OTN Data Managers extensively quality-control submitted metadata to ensure the most accurate records possible are stored in the database. OTN’s database and Data Portal website are well suited for archiving datasets for future use and sharing with collaborators. The OTN system includes pathways to publish datasets with OBIS, and for sharing via open data portals such as ERDDAP and GeoServer. The data-product format returned by OTN is directly ingestible by analysis packages including glatos and resonATe. OTN offers continuous support for the use of these packages and tools.
For your interest, we have included here a presentation from current Node Managers, describing the relationship between OTN and its Nodes, the benefits of the Node system as a community outgrows more organic person-to-person sharing, as well as a realistic understanding of the work involved in hosting/maintaining a Node.
Node Managers
To date, the greatest successes in organizing telemetry communities has come from identifying and working with local on-the-ground Node Managers for each affiliated Node. The trusted and connected ‘data wranglers’ have been essential to building and maintaining the culture and sense of trust in each telemetry group.
Node Managers have been trained from groups including FACT, ACT, SAF, PATH, PIRAT and MigraMar. OTNDC staff assist with node management for NEP, SAF and OTN.
Node Training
Each year OTN hosts a training session for Node Managers. This session is not only for new Node Managers, but also a refresher for current Node Managers on our updated tools and processes.
Data Partners
In addition to OTN-supported nodes, we partner with numerous telemetry networks to ensure that effort and science is shared regardless of disparate database structures. Data system cross-walk efforts continue with ETN, IMOS and GLATOS.
Key Points
Nodes help telemetry researchers stay connected
Nodes are fully compatible
OTN supports Node Managers
OTN System, Structure and Outputs
Overview
Teaching: 25 min
Exercises: 0 minQuestions
What does an OTN-style Database look like?
What is the general path data takes through the OTN data system
What does the OTN data system output?
Objectives
Understand the OTN Database structure on a high level
Understand the general path of data of data through the OTN system
Understand what the OTN system can output
OTN Data System
The OTN data system is an aggregator of telemetry data made up of interconnected Node Databases and data processing tools. These work together to connect researchers with relevant and reliable data. At the heart of this system are Nodes and their OTN-style Databases.
Affiliated acoustic telemetry partner Networks may become an OTN Node by deploying their own database that follows the same structure as all the others. This structure allows Nodes to use OTN’s data loading processes, produce OTN data products, and match detections across other Nodes.
Basic Structure
The basic structural decision at the centre of an OTN-style Database is that each of a Node’s projects will be subdivided into their own database schemas. These schemas contain only the relevant tables and data to that project. The tables included in each schema are created and updated based on which types of data each project is reporting.
Projects can have the type tracker, deployment, or data.
- Tracker projects only submit data about tag-releases and animals. They get tables based on the tags, animals, and detections of those tags.
- Deployment projects only submit data about receivers and their collected data. These projects get tables related to receiver deployments and detections on their receivers.
- Data projects are projects that deploy both tags and receivers and will submit data related tags, animals, receivers, and detections and will get all the related tables.
In addition to the project-specific schemas, there are some important common schemas in the Database that Node Managers will interact with. These additional schemas include the obis, erddap, geoserver, vendor, and discovery schemas. These schemas are found across all Nodes and are used to create important end-products and for processing.
- The
obisschema holds summary data describing each project contained in the Node as well as the aggregated data from those projects. When data goes into a final table of the project schema it will be inherited into a table inobis(generally with a similar name). - The
erddapschema holds aggregated data re-formatted to be used to serve telemetry data via an ERDDAP data portal. - The
geoserverschema holds aggregated data re-formatted to be used to create geospatial data products published to a GeoServer. - The
vendorschema holds manufacturer specifications for tags and receivers, used for quality control purposes. - The
discoveryschema holds summaries of data across the OTN ecosystem. These tables are used to create summary reports and populate statistics and maps on partner webpages.
The amount of information shared through the discovery tables can be adjusted based on sharing and reporting requirements for each Node.

The Path of Data
The OTN data system takes 4 types of data/metadata: project, tag, instrument deployments, and detections. Most data has a similar flow through the OTN system even though each type has different notebooks and processes for loading. The exception to this is project metadata which has a more unique journey because it is completely user-defined, and must be used to initially define and create a project’s schema.
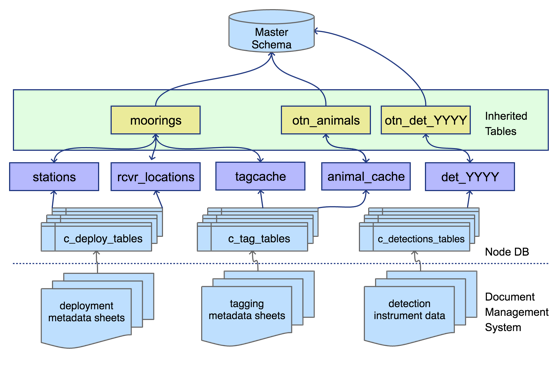
Project Data
Project data has a unique workflow from the other input data and metadata that flows into an OTN Node, it is generally the first bit of information received about a project, and will be used to create the new schema in the Database for a project. The type of project selected (tracker, deployment, or data) will determine the format of the tables in the newly created schema. The type of project will also impact the loading tools and processes that will be used later on. The general journey of project data is:
- To register a new project a researcher will fill out a
project metadatatemplate and submit it to the Node Manager. - The Node Manager will visually evaluate the template to catch any obvious errors and then runs the data through the OTN Nodebook responsible for creating and updating projects (
Create and Update Projects). - The
Create and Update Projectsnotebook will make a new schema in the Database for that project, and fill it with the required tables based on the type of project. - Summary tables are populated at this time (
scientificnames,contacts,otn_resourcesetc). - After this, OTN will verify the project one last time to make sure every necessary field is filled out and properly defined.
Tag, Deployment and Detections Data
Even though tag, deployment, and detections data all have their own loading tools and processes, their general path through the database is the same.
- Their data workflows all begin with a submission of data or metadata files from a researcher.
- The Node Manager ensures there is a copy of the file on the Node’s document management website.
- They will then do some quick visual QC to catch any obvious errors.
- The data is then processed through the relevant OTN Nodebooks. This process is outlined by the task list associated with the GitLab Issue made for this data.
- The data will first be loaded into the
rawtables. This is the table that holds the raw data as submitted by the researcher (the naming convention for raw tables: they always have the prefixc_and will have a suffix indicating the date it was loaded, typicallyYYYY_MM). - After the raw data table is verified, the data will move to the
intermediatetables which hold partially-processed data as a “staging area”. - After the intermediate table is verified, data will move to the
uppertables, where the data is finished processing and is in its “final form”. This is the data that will be used for aggregation tables such asobisand for outputs such asDetection Extracts.
OTN Data Products
The OTN Database has specific data products available, based upon the clean processed data, for researchers to use for their scientific analysis.
In order to create meaningful Detection Extracts, OTN and affiliated Nodes only perform cross-matching events every 4 months (when a reasonable amount of new data has been processed). This event is called a synchronous Data Push. In a Data Push:
- All recently-loaded data is verified and updated.
- Cross-node matching is done; where detections are matched to their relevant tag, across all Nodes.
- Once cross-node matching is done, Detection Extracts are created, containing all the new detections matches for each project. Detection Extract files are formatted for direct ingestion by analysis packages such as glatos and resonate.
- Summary schemas like
discovery,erddap, andgeoserverare updated with the newly verified and updated data. - Summary schema records can be used to create maps and other record overviews such as this map of active OTN receivers:
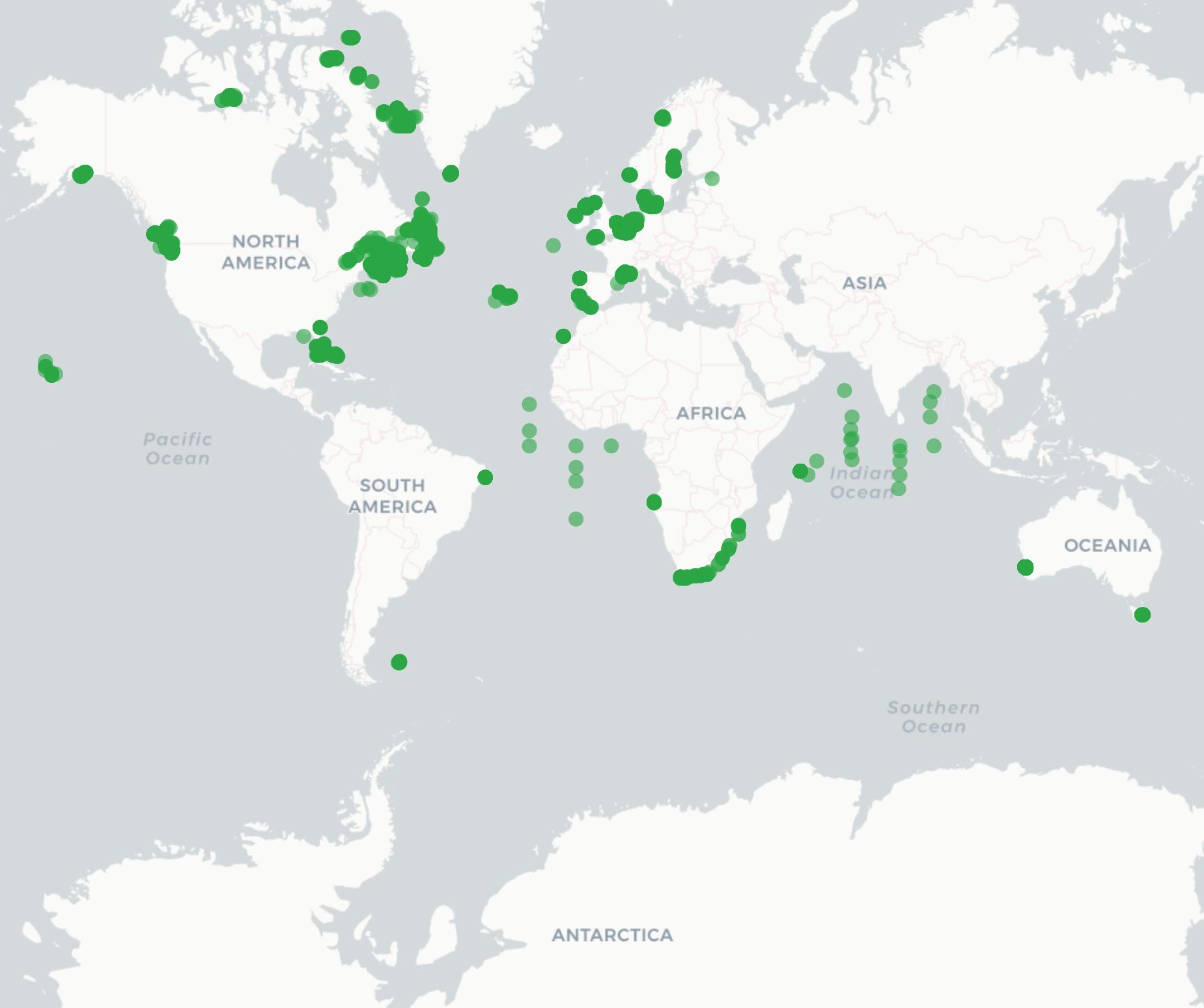
Backing Up Your Data
OTN data systems are designed with redundancy that ensures zero data loss in the event of any hardware failure. OTN has a plan in place for data archiving with CIOOS, should the network cease to be supported by our funding agency.
Key Points
All OTN-style Databases have the same structure
Databases are divided into project schemas which get certain tables based on the type of data they collect
Data in the OTN system moves from the raw tables to the intermediate tables to the upper tables before aggregation
Data Push
Overview
Teaching: 10 min
Exercises: 0 minQuestions
What is a Data Push?
What are the end products of a Data Push?
Objectives
Understand a basic overview of a Data Push
Understand the format of Detection Extracts
What is a Data Push?
A Data Push is when the OTN data system is re-verified and any new relevant information is sent to researchers. New data being brought in is cut off so that what’s in the system can be reliably verified. This way any issues found can be fixed and the data can be in the best form based on the information available at that moment. Once verification is done detections are matched across nodes and detection extracts are sent out to researchers. This is also the time when summary schemas like discovery, erddap, and geoserver are updated with the newly verified and updated data.
What is the Push Schedule?
Push events happen three times a year. They start on the third Thursday of the “push month” which are February, June, and October. This date is the cut-off date for all data-loading: no records can be loaded after this until important verification and processing tasks are completed.
With the increased number of Nodes joining the Pushes, we are announcing the schedule for the next year. Please prepare in advance and mark your calendars.
Push schedule through 2023:
- June 23, 2022
- October 20, 2022
- February 16, 2023
- June 15, 2023
- October 19, 2023
Activities During the Push
Both node managers and data analysts have important roles during a push:
Node Managers need to ensure that the following is done:
- The first job is to get the Node’s data loaded in time for the cut-off date. Data is submitted by researchers on a continuous basis, and generally increases just before a cut-off date. We prioritize loading data as it arrives, to attempt to prevent a backlog near the Push date.
- The second job for Node Managers is to create and send out Detection Extracts when they are ready to be made. This is done using a custom jupyter notebook written in Python.
Once the cut-off date has passed Node Managers are “off duty”, then when it’s time for Detection Extracts to be created and disseminated that task is assigned to the Node Managers, but this does not signify the end of the Push. There are several more “behind the scenes” steps required.
Data Analysts have many jobs during a Push, including:
- verify all schemas and all data types
- verify all inherited tables for structure, permissions, and data formatting
- perform cross-node matching
- run the “discovery process” to update the summary tables
- perform robust back-ups
- push data into production databases
- repopulate our website
Detection Extracts
Detection Extracts are the main output of the Push. They contain all the new detection matches for each project. There are multiple types of detection extracts OTN creates:
- ‘qualified’ which contain detections collected by an array but matched to animals of other projects
- ‘unqualified’ which contain the unmatched or mystery detections collected by an array
- ‘sentinel’ which contain the detections matched to test or transceiver tags collected by an array
- ‘tracker’ which contains detections that have been mapped to animals tagged by a project that can originate from any receiver in the entire Network
Detection Extract files are formatted for direct ingestion by analysis packages such as glatos and resonate. They use DarwinCore terminology where relevant.
Detection Extract Creation
During the Push process, any new detection matches that are made are noted in the Node’s detection_extracts table. These entries will have several pieces of useful information:
detection_extract: this contains the project code, year, and type of extract that needs to be created.- ex:
ABC,2022,twill suggest that project ABC needs the extractmatched to animals 2022(tracker format) created.
- ex:
git_issue_link: the GitLab issue in which these detection matches were impactedpush_date: the date of the Push when this extract will have to be made
Using these fields, the detections-create detection extracts jupyter notebook can determine which extracts need to be created for each push. During this notebook, all relevant contacts (based on folder access in the Data Portal repository) are identified and notified via email of their new detection products.
Once all extracts are made and uploaded to the file management system, and all emails have been sent to researchers, the final step is to ensure we mark in the database table that we have completed these tasks.
Key Points
A Data Push is when we verify all the data in the system, fix any issues, and then provide detection matches to researchers
Detection Extracts are the main end product of the Push
Beyond Telemetry
Overview
Teaching: 0 min
Exercises: 0 minQuestions
In what other ways does OTN support animal telemetry researchers?
Objectives
Beyond Telemetry Reporting
OTN serves the telemetry and broader scientific community through its primary purpose, as a data aggregation node, but that is not where the community support ends. In addition to curating and brokering interproject telemetry records, OTN has the following aspects:
OBIS publishing
OTN is an OBIS thematic node, tasked with curating and coordinating the publishing of aquatic animal tracking data. OTN adheres closely to Darwin Core standards throughout the data reporting process. OTN is involved with the training of OBIS members and development of tools and processes, through training workshops and code sprints.
DOI minting
OTN creates DOI data sets when requested by researchers. These DOIs primarily support publications and descriptive links are held on the OTN Data Portal publication data repository.
Study Halls
To reduce the stress of working in isolation, especially for early career researchers, OTN established a weekly ‘Study Hall’ session. Networking and collaborative problem solving in a virtual setting are hosted with a broad geographic attendance.

Workshops
OTN has hosted many workshops in the past which contain different code sets relating to telemetry analysis. Many of our Intro to R workshops are based upon this curriculum from The Carpentries.
- OTN’s Workshop Base Code
- This is used to create custom workshops when requested.
Past custom workshops with repositories and webpages:
-
IdeasOTN Telemetry Workshop Series 2020: code repository and YouTube recordings
Key Points
OTN provides support to researchers in many ways