OTN Collaboration Update
Overview
Teaching: 0 min
Exercises: 0 minQuestions
What is the Ocean Tracking Network?
How does the GLATOS Network interact with OTN?
Objectives
The Ocean Tracking Network (OTN) supports global telemetry research by providing training, equipment, and data infrastructure to our large network of partners. The GLATOS Network continues to be an important OTN partner, now hosting a compatible Database Node and other cross-referencing tools. OTN supports GLATOS through the collaborative development of the glatos R package and training by means of annual workshops as part of the GLATOS Annual Coordination Meeting.
Learn more about OTN and our partners here https://members.oceantrack.org/
Learn more about GLATOS and their community here https://glatos.glos.us/
This curriculum has been developed by several collaborators. If you have questions please reach out to otndc@dal.ca.
On behalf of OTN, we hope you enjoy this workshop!
Key Points
Intro to R
Overview
Teaching: 30 min
Exercises: 20 minQuestions
What are common operators in R?
What are common data types in R?
What are some base R functions?
How do I deal with missing data?
Objectives
First, lets learn about RStudio.
RStudio is divided into 4 “Panes”: the Source for your scripts and documents (top-left, in the default layout); your Environment/History (top-right) which shows all the objects in your working space (Environment) and your command history (History); your Files/Plots/Packages/Help/Viewer (bottom-right); and the R Console (bottom-left). The placement of these panes and their content can be customized (see menu, Tools -> Global Options -> Pane Layout).
The R Script in the top pane can be saved and edited, while code typed directly into the Console below will disappear after closing the R session.
R can access files on and save outputs to any folder on your computer. R knows where to look for and save files based on the current working directory. This is one of the first things you should set up: a folder you’d like to contain all your data, scripts and outputs. The working directory path will be different for everyone.
Setting up R
# Packages ####
# once you install packages to your computer, you can "check them out" of your packages library each time you need them
# make sure you check the "mask" messages that appear - sometimes packages have functions with the same names!
library(tidyverse)# really neat collection of packages! https://www.tidyverse.org/
library(lubridate)
library(readxl)
library(viridis)
library(plotly)
library(ggmap)
# Working Directory ####
setwd('C:/Users/ct991305/Documents/Workshop Material/2021-03-30-glatos-workshop/data/') #set folder you're going to work in
getwd() #check working directory
#you can also change it in the RStudio interface by navigating in the file browser where your working directory should be
#(if you can't see the folder you want, choose the three horizonal dots on the right side of the Home bar),
#and clicking on the blue gear icon "More", and select "Set As Working Directory".
Intro to R
Like most programming langauges, we can do basic mathematical operations with R. These, along with variable assignment, form the basis of everything for which we will use R.
Operators
3 + 5 #maths! including - , *, /
weight_kg <- 55 #assignment operator! for objects/variables. shortcut: alt + -
weight_kg
weight_lb <- 2.2 * weight_kg #can assign output to an object. can use objects to do calculations
Variables Challenge
If we change the value of weight_kg to be 100, does the value of weight_lb also change? Remember: You can check the contents of an object by typing out its name and running the line in RStudio.
Functions
#functions take "arguments": you have to tell them what to run their script against
ten <- sqrt(weight_kg) #contain calculations wrapped into one command to type.
round(3.14159) #don't have to assign
args(round) #the args() function will show you the required arguments of another function
?round #will show you the full help page for a function, so you can see what it does
Functions Challenge
Can you round the value 3.14159 to two decimal places? Hint: Using args() on a function can give you a clue.
Vectors and Data Types
weight_g <- c(21, 34, 39, 54, 55) #use the combine function to join values into a vector object
length(weight_g) #explore vector
class(weight_g) #a vector can only contain one data type
str(weight_g) #find the structure of your object.
#our vector is numeric.
#other options include: character (words), logical (TRUE or FALSE), integer etc.
animals <- c("mouse", "rat", "dog") #to create a character vector, use quotes
# Note:
#R will convert (force) all values in a vector to the same data type.
#for this reason: try to keep one data type in each vector
#a data table / data frame is just multiple vectors (columns)
#this is helpful to remember when setting up your field sheets!
Vectors Challenge
What data type will this vector become?
challenge3 <- c(1, 2, 3, "4")Hint: You can check a vector’s type with the class() function.
Subsetting
animals #calling your object will print it out
animals[2] #square brackets = indexing. selects the 2nd value in your vector
weight_g > 50 #conditional indexing: selects based on criteria
weight_g[weight_g <=30 | weight_g == 55] #many new operators here!
#<= less than or equal to, | "or", == equal to
weight_g[weight_g >= 30 & weight_g == 21] # >= greater than or equal to, & "and"
# this particular example give 0 results - why?
Missing Data
heights <- c(2, 4, 4, NA, 6)
mean(heights) #some functions cant handle NAs
mean(heights, na.rm = TRUE) #remove the NAs before calculating
#other ways to get a dataset without NAs:
heights[!is.na(heights)] #select for values where its NOT NA
#[] square brackets are the base R way to select a subset of data --> called indexing
#! is an operator that reverses the function
na.omit(heights) #omit the NAs
heights[complete.cases(heights)] #select only complete cases
Missing Data Challenge
Question 1: Using the following vector of heighs in inches, create a new vector, called heights_no_na, with the NAs removed.
heights <- c(63, 69, 60, 65, NA, 68, 61, 70, 61, 59, 64, 69, 63, 63, NA, 72, 65, 64, 70, 63, 65)Question 2: Use the function median() to calculate the median of the heights vector.
Bonus question: Use R to figure out how many people in the set are taller than 67 inches.
Key Points
Starting with Data Frames
Overview
Teaching: 25 min
Exercises: 10 minQuestions
How do I import tabular data?
How do I explore my data set?
What are some basic data manipulation functions?
Objectives
Importing from csv
dplyr takes advantage of tidyverse pipes and chains of data manipulation to create powerful exploratory summaries.
If you’re unfamiliar with detection extracts formats from OTN-style database nodes, see the documentation here
#imports file into R. paste the filepath to the unzipped file here!
lamprey_dets <- read_csv("inst_extdata_lamprey_detections.csv", guess_max = 3102)
#read_csv() is from tidyverse's readr package --> you can also use read.csv() from base R but it created a dataframe (not tibble) so loads slower
#see https://link.medium.com/LtCV6ifpQbb
#the guess_max argument is helpful when there are many rows of NAs at the top. R will not assign a data type to that columns until it reaches the max guess.
#I chose to use this here because I got the following warning from read_csv()
# Warning: 4497 parsing failures.
#row col expected actual file
#3102 sensor_value 1/0/T/F/TRUE/FALSE 66.000 'inst_extdata_lamprey_detections.csv'
#3102 sensor_unit 1/0/T/F/TRUE/FALSE ADC 'inst_extdata_lamprey_detections.csv'
##3102 glatos_caught_date 1/0/T/F/TRUE/FALSE 2012-07-04 'inst_extdata_lamprey_detections.csv'
#3103 sensor_value 1/0/T/F/TRUE/FALSE 62.000 'inst_extdata_lamprey_detections.csv'
#3103 sensor_unit 1/0/T/F/TRUE/FALSE ADC 'inst_extdata_lamprey_detections.csv'
Exploring Detection Extracts
Let’s start with a practical example. What can we find out about these matched detections?
head(lamprey_dets) #first 6 rows
View(lamprey_dets) #can also click on object in Environment window
str(lamprey_dets) #can see the type of each column (vector)
glimpse(lamprey_dets) #similar to str()
#summary() is a base R function that will spit out some quick stats about a vector (column)
#the $ syntax is the way base R selects columns from a data frame
summary(lamprey_dets$release_latitude)
Detection Extracts Challenge
Question 1: What is the class of the station column in lamprey_dets?
Question 2: How many rows and columns are in the lamprey_dets dataset?
Data Manipulation
What is dplyr and how can it be used to create summaries for me?
library(dplyr) #can use tidyverse package dplyr to do exploration on dataframes in a nicer way
# %>% is a "pipe" which allows you to join functions together in sequence.
#it can be read as "and then". shortcut: ctrl + shift + m
lamprey_dets %>% dplyr::select(6) #selects column 6
# dplyr::select this syntax is to specify that we want the select function from the dplyr package.
#often functions are named the same but do diff things
lamprey_dets %>% slice(1:5) #selects rows 1 to 5 dplyr way
lamprey_dets %>%
distinct(glatos_array) %>%
nrow #number of arrays that detected my fish in dplyr! first: find the distinct values, then count
lamprey_dets %>%
distinct(animal_id) %>%
nrow #number of animals that were detected
lamprey_dets %>% filter(animal_id=="A69-1601-1363") #filtering in dplyr!
lamprey_dets %>% filter(detection_timestamp_utc >= '2012-06-01 00:00:00') #all dets on/after June 1 2012 - conditional filtering!
#get the mean value across a column using GroupBy and Summarize
lamprey_dets %>%
group_by(animal_id) %>% #we want to find meanLat for each animal
summarise(MeanLat=mean(deploy_lat)) #uses pipes and dplyr functions to find mean latitude for each fish.
#we named this new column "MeanLat" but you could name it anything
Data Manipulation Challenge
Question 1: Find the max lat and max long for animal “A69-1601-1363”.
Question 2: Find the min lat/long of each animal for detections occurring in July 2012.
Dealing with Datetimes
Datetimes are special formats which are not numbers nor characters.
library(lubridate)
lamprey_dets %>% mutate(detection_timestamp_utc=ymd_hms(detection_timestamp_utc)) #Tells R to treat this column as a date, not number numbers
#as.POSIXct(lamprey_dets$detection_timestamp_utc) #this is the base R way - if you ever see this function
#lubridate is amazing if you have a dataset with multiple datetime formats / timezone
#the function parse_date_time() can be used to specify multiple date formats if you have a dataset with mixed rows
#the function with_tz() can change timezone. accounts for daylight savings too!
#example code to change timezone:
#My_Data_Set %>% mutate(datetime = ymd_hms(datetime, tz = "America/Nassau")) #change your column to a datetime format, specifying TZ (eastern)
#My_Data_Set %>% mutate(datetime_utc = with_tz(datetime, tzone = "UTC")) #make new column called datetime_utc which is datetime converted to UTC
Key Points
Intro to Plotting
Overview
Teaching: 15 min
Exercises: 10 minQuestions
How do I plot my data?
How can I plot summaries of my data?
Objectives
Learn how to make basic plots with ggplot2
Learn how to combine dplyr summaries with ggplot2 plots
Background
ggplot2 takes advantage of tidyverse pipes and chains of data manipulation as well as separating the aesthetics of the plot (what are we plotting) from the styling of the plot (how should we show it?), in order to produce readable and malleable plotting code.
general formula ggplot(data = <DATA>, mapping = aes(<MAPPINGS>)) + <GEOM_FUNCTION>()
library(ggplot2) #tidyverse-style plotting, a very customizable plotting package
# Assign plot to a variable
lamprey_dets_plot <- ggplot(data = lamprey_dets,
mapping = aes(x = deploy_lat, y = deploy_long)) #can assign a base plot to data
# Draw the plot
lamprey_dets_plot +
geom_point(alpha=0.1,
colour = "blue")
#layer whatever geom you want onto your plot template
#very easy to explore diff geoms without re-typing
#alpha is a transparency argument in case points overlap. Try alpha = 0.02 to see how it works!
Basic plots
You can build your plots iteratively, without assigning to a variale as well.
lamprey_dets %>%
ggplot(aes(deploy_lat, deploy_long)) + #aes = the aesthetic/mappings. x and y etc.
geom_point() #geom = the type of plot
lamprey_dets %>%
ggplot(aes(deploy_lat, deploy_long, colour = animal_id)) + #colour by individual! specify in the aesthetic
geom_point()
#anything you specify in the aes() is applied to the actual data points/whole plot,
#anything specified in geom() is applied to that layer only (colour, size...). sometimes you have >1 geom layer so this makes more sense!
Challenge
Try combining with dplyr functions in this challenge!
#Challenge 7: try making a scatterplot showing the lat/long for animal "A69-1601-1363", coloured by detection array
#Question: what other geoms are there? Try typing `geom_` into R to see what it suggests!
Plotting and dplyr Challenge
Combine dplyr functions to solve this challenge.
Try making a scatterplot showing the lat/long for animal “A69-1601-1363”, coloured by detection array.
What other geoms are there? Try typing ‘geom_’ into R and see what it suggests!
Key Points
You can feed output from dplyr’s data manipulation functions into ggplot using pipes.
Plotting various summaries and groupings of your data is good practice at the exploratory phase, and dplyr and ggplot make iterating different ideas straightforward.
Telemetry Reports - Imports
Overview
Teaching: 10 min
Exercises: 0 minQuestions
What datasets do I need from the Node?
How do I import all the datasets?
Objectives
Importing all the datasets
Now that we have an idea of what an exploratory workflow might look like with Tidyverse libraries like dplyr and ggplot2, let’s look at how we might implement a common telemetry workflow using these tools.
View(lamprey_dets) #already have our Lamprey tag matches
#import walleye dets
walleye_dets <- read_csv("inst_extdata_walleye_detections.csv", guess_max = 9595) #remember guess_max from prev section!
#Warning: 9595 parsing failures.
#row col expected actual file
#3047 sensor_value 1/0/T/F/TRUE/FALSE 11 'inst_extdata_walleye_detections.csv'
#3047 sensor_unit 1/0/T/F/TRUE/FALSE ADC 'inst_extdata_walleye_detections.csv'
#3048 sensor_value 1/0/T/F/TRUE/FALSE 11 'inst_extdata_walleye_detections.csv'
#3048 sensor_unit 1/0/T/F/TRUE/FALSE ADC 'inst_extdata_walleye_detections.csv'
#3049 sensor_value 1/0/T/F/TRUE/FALSE 11 'inst_extdata_walleye_detections.csv'
#lets join these two detection files together!
all_dets <- rbind(lamprey_dets, walleye_dets)
# lets import GLATOS receiver station data for the whole network
glatos_receivers <- read_csv("inst_extdata_sample_receivers.csv")
View(glatos_receivers)
#Lets import our workbook now!
library(readxl)
walleye_deploy <- read_excel('inst_extdata_walleye_workbook.xlsm', sheet = 'Deployment') #pull in deploy
View(walleye_deploy)
walleye_recovery <- read_excel('inst_extdata_walleye_workbook.xlsm', sheet = 'Recovery') #pull in recovery
View(walleye_recovery)
#join the deploy and recovery sheets together
walleye_recovery <- walleye_recovery %>% rename(INS_SERIAL_NO = INS_SERIAL_NUMBER) #first, rename INS_SERIAL_NUMBER
walleye_recievers = merge(walleye_deploy, walleye_recovery,
by.x = c("GLATOS_PROJECT", "GLATOS_ARRAY", "STATION_NO",
"CONSECUTIVE_DEPLOY_NO", "INS_SERIAL_NO"),
by.y = c("GLATOS_PROJECT", "GLATOS_ARRAY", "STATION_NO",
"CONSECUTIVE_DEPLOY_NO", "INS_SERIAL_NO"),
all.x=TRUE, all.y=TRUE) #keep all the info from each, merged using the above columns
View(walleye_recievers)
#need Tagging metadata too!
walleye_tag <- read_excel('inst_extdata_walleye_workbook.xlsm', sheet = 'Tagging')
View(walleye_tag)
#remember: we learned how to switch timezone of datetime columns above,
# if that is something you need to do with your dataset!!
#hint: check GLATOS_TIMEZONE column to see if its what you want!
#the glatos R package (will be reviewed in the workshop tomorrow) can import your workbook in one step
#will format all datetimes to UTC, check for conflicts, join the deploy/recovery tabs etc.
library(glatos) #this won't work unless you happen to have this installed - just an teaser today, will be covered tomorrow
data <- read_glatos_workbook('inst_extdata_walleye_workbook.xlsm')
receivers <- data$receivers
animals <- data$animals
Key Points
Telemetry Reports for Array Operators
Overview
Teaching: 30 min
Exercises: 0 minQuestions
How do I summarize and plot my deployments?
How do I summarize and plot my detections?
Objectives
Mapping GLATOS stations - Static map
This section will use the Receivers CSV for the entire GLATOS Network.
library(ggmap)
#first, what are our columns called?
names(glatos_receivers)
#make a basemap for all of the stations, using the min/max deploy lat and longs as bounding box
#what are our columns called?
names(glatos_receivers)
base <- get_stamenmap(
bbox = c(left = min(glatos_receivers$deploy_long),
bottom = min(glatos_receivers$deploy_lat),
right = max(glatos_receivers$deploy_long),
top = max(glatos_receivers$deploy_lat)),
maptype = "terrain-background",
crop = FALSE,
zoom = 8)
#filter for stations you want to plot - this is very customizable
glatos_deploy_plot <- glatos_receivers %>%
mutate(deploy_date=ymd_hms(deploy_date_time)) %>% #make a datetime
mutate(recover_date=ymd_hms(recover_date_time)) %>% #make a datetime
filter(!is.na(deploy_date)) %>% #no null deploys
filter(deploy_date > '2011-07-03' & recover_date < '2018-12-11') %>% #only looking at certain deployments, can add start/end dates here
group_by(station, glatos_array) %>%
summarise(MeanLat=mean(deploy_lat), MeanLong=mean(deploy_long)) #get the mean location per station, in case there is >1 deployment
# you could choose to plot stations which are within a certain bounding box!
#to do this you would add another filter to the above data, before passing to the map
# ex: add this line after the mutate() clauses:
# filter(latitude <= 0.5 & latitude >= 24.5 & longitude <= 0.6 & longitude >= 34.9)
#add your stations onto your basemap
glatos_map <-
ggmap(base, extent='panel') +
ylab("Latitude") +
xlab("Longitude") +
geom_point(data = glatos_deploy_plot, #filtering for recent deployments
aes(x = MeanLong,y = MeanLat, colour = glatos_array), #specify the data
shape = 19, size = 2) #lots of aesthetic options here!
#view your receiver map!
glatos_map
#save your receiver map into your working directory
ggsave(plot = glatos_map, filename = "glatos_map.tiff", units="in", width=15, height=8)
#can specify location, file type and dimensions
Mapping our stations - Static map
This section will use the Deployment and Recovery metadata for our array, from our Workbook.
base <- get_stamenmap(
bbox = c(left = min(walleye_recievers$DEPLOY_LONG),
bottom = min(walleye_recievers$DEPLOY_LAT),
right = max(walleye_recievers$DEPLOY_LONG),
top = max(walleye_recievers$DEPLOY_LAT)),
maptype = "terrain-background",
crop = FALSE,
zoom = 8)
#filter for stations you want to plot - this is very customizable
walleye_deploy_plot <- walleye_recievers %>%
mutate(deploy_date=ymd_hms(GLATOS_DEPLOY_DATE_TIME)) %>% #make a datetime
mutate(recover_date=ymd_hms(GLATOS_RECOVER_DATE_TIME)) %>% #make a datetime
filter(!is.na(deploy_date)) %>% #no null deploys
filter(deploy_date > '2011-07-03' & is.na(recover_date)) %>% #only looking at certain deployments, can add start/end dates here
group_by(STATION_NO, GLATOS_ARRAY) %>%
summarise(MeanLat=mean(DEPLOY_LAT), MeanLong=mean(DEPLOY_LONG)) #get the mean location per station, in case there is >1 deployment
#add your stations onto your basemap
walleye_deploy_map <-
ggmap(base, extent='panel') +
ylab("Latitude") +
xlab("Longitude") +
geom_point(data = walleye_deploy_plot, #filtering for recent deployments
aes(x = MeanLong,y = MeanLat, colour = GLATOS_ARRAY), #specify the data
shape = 19, size = 2) #lots of aesthetic options here!
#view your receiver map!
walleye_deploy_map
#save your receiver map into your working directory
ggsave(plot = walleye_deploy_map, filename = "walleye_deploy_map.tiff", units="in", width=15, height=8)
#can specify location, file type and dimensions
Mapping my stations - Interactive map
An interactive map can contain more information than a static map.
library(plotly)
#set your basemap
geo_styling <- list(
fitbounds = "locations", visible = TRUE, #fits the bounds to your data!
showland = TRUE,
showlakes = TRUE,
lakecolor = toRGB("blue", alpha = 0.2), #make it transparent
showcountries = TRUE,
landcolor = toRGB("gray95"),
countrycolor = toRGB("gray85")
)
#decide what data you're going to use
glatos_map_plotly <- plot_geo(glatos_deploy_plot, lat = ~MeanLat, lon = ~MeanLong)
#add your markers for the interactive map
glatos_map_plotly <- glatos_map_plotly %>% add_markers(
text = ~paste(station, MeanLat, MeanLong, sep = "<br />"),
symbol = I("square"), size = I(8), hoverinfo = "text"
)
#Add layout (title + geo stying)
glatos_map_plotly <- glatos_map_plotly %>% layout(
title = 'GLATOS Deployments<br />(> 2011-07-03)', geo = geo_styling
)
#View map
glatos_map_plotly
How are my stations performing?
Let’s find out more about the animals detected by our array!
#How many detections of my tags does each station have?
det_summary <- all_dets %>%
filter(glatos_project_receiver == 'HECST') %>% #choose to summarize by array, project etc!
mutate(detection_timestamp_utc=ymd_hms(detection_timestamp_utc)) %>%
group_by(station, year = year(detection_timestamp_utc), month = month(detection_timestamp_utc)) %>%
summarize(count =n())
det_summary #number of dets per month/year per station
#How many detections of my tags does each station have? Per species
anim_summary <- all_dets %>%
filter(glatos_project_receiver == 'HECST') %>% #choose to summarize by array, project etc!
mutate(detection_timestamp_utc=ymd_hms(detection_timestamp_utc)) %>%
group_by(station, year = year(detection_timestamp_utc), month = month(detection_timestamp_utc), common_name_e) %>%
summarize(count =n())
anim_summary #number of dets per month/year per station & species
Key Points
Telemetry Reports for Tag Owners
Overview
Teaching: 30 min
Exercises: 0 minQuestions
How do I summarize and plot my detections?
How do I summarize and plot my tag metadata?
Objectives
Mapping my Detections and Releases - static map
Where were my fish observed?
base <- get_stamenmap(
bbox = c(left = min(all_dets$deploy_long),
bottom = min(all_dets$deploy_lat),
right = max(all_dets$deploy_long),
top = max(all_dets$deploy_lat)),
maptype = "terrain-background",
crop = FALSE,
zoom = 8)
#add your detections onto your basemap
detections_map <-
ggmap(base, extent='panel') +
ylab("Latitude") +
xlab("Longitude") +
geom_point(data = all_dets,
aes(x = deploy_long,y = deploy_lat, colour = common_name_e), #specify the data
shape = 19, size = 2) #lots of aesthetic options here!
#view your detections map!
detections_map
Mapping my Detections and Releases - interactive map
Let’s use plotly!
#set your basemap
geo_styling <- list(
fitbounds = "locations", visible = TRUE, #fits the bounds to your data!
showland = TRUE,
showlakes = TRUE,
lakecolor = toRGB("blue", alpha = 0.2), #make it transparent
showcountries = TRUE,
landcolor = toRGB("gray95"),
countrycolor = toRGB("gray85")
)
#decide what data you're going to use
detections_map_plotly <- plot_geo(all_dets, lat = ~deploy_lat, lon = ~deploy_long)
#add your markers for the interactive map
detections_map_plotly <- detections_map_plotly %>% add_markers(
text = ~paste(animal_id, common_name_e, paste("Date detected:", detection_timestamp_utc),
paste("Latitude:", deploy_lat), paste("Longitude",deploy_long),
paste("Detected by:", glatos_array), paste("Station:", station),
paste("Project:",glatos_project_receiver), sep = "<br />"),
symbol = I("square"), size = I(8), hoverinfo = "text"
)
#Add layout (title + geo stying)
detections_map_plotly <- detections_map_plotly %>% layout(
title = 'Lamprey and Walleye Detections<br />(2012-2013)', geo = geo_styling
)
#View map
detections_map_plotly
Summary of tagged animals
This section will use your Tagging Metadata
# summary of animals you've tagged
walleye_tag_summary <- walleye_tag %>%
mutate(GLATOS_RELEASE_DATE_TIME = ymd_hms(GLATOS_RELEASE_DATE_TIME)) %>%
#filter(GLATOS_RELEASE_DATE_TIME > '2012-06-01') %>% #select timeframe, specific animals etc.
group_by(year = year(GLATOS_RELEASE_DATE_TIME), COMMON_NAME_E) %>%
summarize(count = n(),
Meanlength = mean(LENGTH, na.rm=TRUE),
minlength= min(LENGTH, na.rm=TRUE),
maxlength = max(LENGTH, na.rm=TRUE),
MeanWeight = mean(WEIGHT, na.rm = TRUE))
#view our summary table
walleye_tag_summary
Detection Attributes
Lets add some biological context to our summaries!
#Average location of each animal!
all_dets %>%
group_by(animal_id) %>%
summarize(NumberOfStations = n_distinct(station),
AvgLat = mean(deploy_lat),
AvgLong =mean(deploy_long))
# Avg length per location
all_dets_summary <- all_dets %>%
mutate(detection_timestamp_utc = ymd_hms(detection_timestamp_utc)) %>%
group_by(glatos_array, station, deploy_lat, deploy_long, common_name_e) %>%
summarise(AvgSize = mean(length, na.rm=TRUE))
all_dets_summary
#export our summary table as CSV
write_csv(all_dets_summary, "detections_summary.csv", col_names = TRUE)
# count detections per transmitter, per array
all_dets %>%
group_by(transmitter_id, glatos_array, common_name_e) %>%
summarize(count = n()) %>%
select(transmitter_id, common_name_e, glatos_array, count)
# list all glatos arrays each fish was seen on, and a number_of_arrays column too
all_dets %>%
group_by(animal_id) %>%
mutate(arrays = (list(unique(glatos_array)))) %>% #create a column with a list of the arrays
dplyr::select(animal_id, arrays) %>% #remove excess columns
distinct_all() %>% #keep only one record of each
mutate(number_of_arrays = sapply(arrays,length)) %>% #sapply: applies a function across a List - in this case we are applying length()
as.data.frame()
Summary of Detection Counts
Lets make an informative plot showing number of matched detections, per year and month.
all_dets %>%
mutate(detection_timestamp_utc=ymd_hms(detection_timestamp_utc)) %>% #make datetime
mutate(year_month = floor_date(detection_timestamp_utc, "months")) %>% #round to month
filter(common_name_e == 'walleye') %>% #can filter for specific stations, dates etc. doesn't have to be species!
group_by(year_month) %>% #can group by station, species et - doesn't have to be by date
summarize(count =n()) %>% #how many dets per year_month
ggplot(aes(x = (month(year_month) %>% as.factor()),
y = count,
fill = (year(year_month) %>% as.factor())
)
)+
geom_bar(stat = "identity", position = "dodge2")+
xlab("Month")+
ylab("Total Detection Count")+
ggtitle('Walleye Detections by Month (2012-2013)')+ #title
labs(fill = "Year") #legend title
Other Example Plots
Some examples of complex plotting options
# an easy abacus plot!
#Use the color scales in this package to make plots that are pretty,
#better represent your data, easier to read by those with colorblindness, and print well in grey scale.
library(viridis)
abacus_animals <-
ggplot(data = all_dets, aes(x = detection_timestamp_utc, y = animal_id, col = glatos_array)) +
geom_point() +
ggtitle("Detections by animal") +
theme(plot.title = element_text(face = "bold", hjust = 0.5)) +
scale_color_viridis(discrete = TRUE)
abacus_animals
#another way to vizualize
abacus_stations <-
ggplot(data = all_dets, aes(x = detection_timestamp_utc, y = station, col = animal_id)) +
geom_point() +
ggtitle("Detections by station") +
theme(plot.title = element_text(face = "bold", hjust = 0.5)) +
scale_color_viridis(discrete = TRUE)
abacus_stations
#track movement using geom_path!
movMap <-
ggmap(base, extent = 'panel') + #use the BASE we set up before
ylab("Latitude") +
xlab("Longitude") +
geom_path(data = all_dets, aes(x = deploy_long, y = deploy_lat, col = common_name_e)) + #connect the dots with lines
geom_point(data = all_dets, aes(x = deploy_long, y = deploy_lat, col = common_name_e)) + #layer the stations back on
scale_colour_manual(values = c("red", "blue"), name = "Species")+ #
facet_wrap(~animal_id, ncol = 6, nrow=1)+
ggtitle("Inferred Animal Paths")
movMap
# monthly latitudinal distribution of your animals (works best w >1 species)
all_dets %>%
group_by(month=month(detection_timestamp_utc), animal_id, common_name_e) %>% #make our groups
summarise(meanlat=mean(deploy_lat)) %>% #mean lat
ggplot(aes(month %>% factor, meanlat, colour=common_name_e, fill=common_name_e))+ #the data is supplied, but no info on how to show it!
geom_point(size=3, position="jitter")+ # draw data as points, and use jitter to help see all points instead of superimposition
#coord_flip()+ #flip x y, not needed here
scale_colour_manual(values = c("brown", "green"))+ #change the colour to represent the species better!
scale_fill_manual(values = c("brown", "green"))+ #colour of the boxplot
geom_boxplot()+ #another layer
geom_violin(colour="black") #and one more layer
# per-individual contours - lots of plots: called facets!
all_dets %>%
ggplot(aes(deploy_long, deploy_lat))+
facet_wrap(~animal_id)+ #make one plot per individual
geom_violin()
Key Points
Introduction to GLATOS Data Processing
Overview
Teaching: 30 min
Exercises: 0 minQuestions
How do I load my data into GLATOS?
How do I filter out false detections?
How can I consolidate my detections into detection events?
How do I summarize my data?
Objectives
GLATOS is a powerful toolkit that provides a wide range of functionality for loading, processing, and visualizing your data. With it, you can gain valuable insights with quick and easy commands that condense high volumes of base R into straightforward functions, with enough versatility to meet a variety of needs.
First, we must set our working directory and import the relevant library.
## Set your working directory ####
setwd("./data")
library(glatos)
library(tidyverse)
library(VTrack)
Your code may not be in the ‘code/glatos’ folder, so use the appropriate file path for your data.
Next, we will create paths to our detections and receiver files. GLATOS can function with both GLATOS and OTN-formatted data, but the functions are different for each. Both, however, provide a marked performance boost over base R, and Both ensure that the resulting data set will be compatible with the rest of the glatos framework.
We will use the walleye detections from the glatos package.
# Get file path to example walleye data
det_file_name <- system.file("extdata", "walleye_detections.csv",
Remember: you can always check a function’s documentation by typing a question mark, followed by the name of the function.
## GLATOS help files are helpful!! ####
?read_otn_detections
With our file path in hand, we’ll want to use the read_otn_detections function to load our data into a dataframe. In this case, our data is formatted in the FACT style- if it were GLATOS formatted, we would want to use read_glatos_detections() instead.
# Save our detections file data into a dataframe called detections
detections <- read_otn_detections(det_file=det_file_name)
Remember that we can use head() to inspect a few lines of our data to ensure it was loaded properly.
# View first 2 rows of output
head(detections, 2)
With our data loaded, we next want to apply a false filtering algorithm to reduce the number of false detections in our dataset. GLATOS uses the Pincock algorithm to filter probable false detections based on the time lag between detections- tightly clustered detections are weighted as more likely to be true, while detections spaced out temporally will be marked as false.
## Filtering False Detections ####
## ?glatos::false_detections
# write the filtered data (no rows deleted, just a filter column added)
# to a new det_filtered object
detections_filtered <- false_detections(detections, tf=3600, show_plot=TRUE)
head(detections_filtered)
nrow(detections_filtered)
The false_detections function will add a new column to your dataframe, ‘passed_filter’. This contains a boolean value that will tell you whether or not that record passed the false detection filter. That information may be useful on its own merits; for now, we will just use it to filter out the false detections.
# Filter based on the column if you're happy with it.
detections_filtered <- detections_filtered[detections_filtered$passed_filter == 1,]
nrow(detections_filtered) # Smaller than before
With our data properly filtered, we can begin investigating it and developing some insights. GLATOS provides a range of tools for summarizing our data so that we can better see what our receivers are telling us.
We can begin with a summary by animal, which will group our data by the unique animals we’ve detected.
# Summarize Detections ####
#?summarize_detections
#summarize_detections(detections_filtered)
# By animal ====
sum_animal <- summarize_detections(detections_filtered, location_col = 'station', summ_type='animal')
sum_animal
We can also summarize by location, grouping our data by distinct locations.
# By location ====
sum_location <- summarize_detections(detections_filtered, location_col = 'station', summ_type='location')
head(sum_location)
Finally, we can summarize by both dimensions.
# By both dimensions
sum_animal_location <- summarize_detections(det = detections_filtered,
location_col = 'station',
summ_type='both')
head(sum_animal_location)
Summerizing by both dimensions will create a row for each station and each animal pair, let’s filter out the station where the animal wasn’t detected.
# Filter out stations where the animal was NOT detected.
sum_animal_location <- sum_animal_location %>% filter(num_dets > 0)
sum_animal_location
One other method- we can summarize by a subset of our animals as well. If we only want to see summary data for a fixed set of animals, we can pass an array containing the animal_ids that we want to see summarized.
# create a custom vector of Animal IDs to pass to the summary function
# look only for these ids when doing your summary
tagged_fish <- c('22', '23')
sum_animal_custom <- summarize_detections(det=detections_filtered,
animals=tagged_fish,
location_col = 'station',
summ_type='animal')
sum_animal_custom
Alright, we can summarize our data. Let’s move on and see if we can make our dataset more amenable to plotting by reducing it from detections to detection events.
Detection Events differ from detections in that they condense a lot of temporally and spatially clustered detections for a single animal into a single detection event. This is a powerful and useful way to clean up the data, and makes it easier to present and clearer to read. Fortunately, GLATOS lets us to this easily.
# Reduce Detections to Detection Events ####
# ?glatos::detection_events
# arrival and departure time instead of multiple detection rows
# you specify how long an animal must be absent before starting a fresh event
events <- detection_events(detections_filtered,
location_col = 'station', # combines events across different receivers in a single array
time_sep=3600)
head(events)
We can also keep the full extent of our detections, but add a group column so that we can see how they would have been condensed.
# keep detections, but add a 'group' column for each event group
detections_w_events <- detection_events(detections_filtered,
location_col = 'station', # combines events across different receivers in a single array
time_sep=3600, condense=FALSE)
With our filtered data in hand, let’s move on to some visualization.
Key Points
More Features of GLATOS
Overview
Teaching: 15 min
Exercises: 0 minQuestions
What other features does GLATOS offer?
Objectives
GLATOS has some more advanced analystic tools beyond filtering and creating events.
GLATOS can be used to get the residence index of your animals at all the different stations. GLATOS offers 5 different methods for calculating Residence Index, here we will showcase 2 of those. residence_index requires an events objects to create a residence_index, we will use the one from the last lesson.
# Calc residence index using the Kessel method
rik_data <- glatos::residence_index(events,
calculation_method = 'kessel')
rik_data
# Calc residence index using the time interval method, interval set to 6 hours
rit_data <- glatos::residence_index(events,
calculation_method = 'time_interval',
time_interval_size = "6 hours")
rit_data
Both of these methods are similar and will almost always give different results, you can explore them all to see what method works best for your data.
GLATOS strives to be interoperable with other scientific R packages. Currently, we can crosswalk GLATOS data over to the package VTrack. Here’s an example:
?convert_glatos_to_att
# The receiver metadata for the walleye dataset
rec_file <- system.file("extdata",
"sample_receivers.csv", package = "glatos")
receivers <- read_glatos_receivers(rec_file)
ATTdata <- convert_glatos_to_att(detections_filtered, receivers)
# ATT is split into 3 objects, we can view them like this
ATTdata$Tag.Detections
ATTdata$Tag.Metadata
ATTdata$Station.Information
And then you can use your data with the VTrack package. You can call its abacusPlot function to generate an abacus plot:
# Now that we have an ATT dataframe, we can use it in VTrack functions:
# Abacus plot:
VTrack::abacusPlot(ATTdata)
To use the spacial features of VTrack, we have to give the ATT object a coordinate system to use.
# If you're going to do spatial things in ATT:
library(rgdal)
# Tell the ATT dataframe its coordinates are in decimal lat/lon
proj <- CRS("+init=epsg:4326")
attr(ATTdata, "CRS") <-proj
Here’s an example of the Centers of Activity function from VTrack.
?COA
coa <- VTrack::COA(ATTdata)
coa
Let’s take a look at a plot of the COAs from VTrack. We’ll use animal 153 for this.
# Plot a COA
coa153 <- coa %>% filter(Tag.ID == 153)
data(greatLakesPoly) # Get spacial object from glatos package
# plot the object and zoom in to lake Huron. Set colour of water to blue. Add labels to the axises
plot(greatLakesPoly, xlim=c(-85, -82), ylim=c(43, 46), col='blue', xlab="Longitude", ylab="Latitude")
# Create a palette
color <- c(colorRampPalette(c('pink', 'red'))(max(coa153$Number.of.Detections)))
#add the points
points(coa153$Longitude.coa, coa153$Latitude.coa, pch=19, col=color[coa153$Number.of.Detections],
cex=log(coa153$Number.of.Stations) + 0.5) # cex is for point size. natural log is for scaling purposes
# add axises and title
axis(1)
axis(2)
title("Centers of Activities for 153")
Here’s an example of a VTrack function for getting metrics of dispersal.
# Dispersal information
# ?dispersalSummary
dispSum<-dispersalSummary(ATTdata)
View(dispSum)
# Get only the detections when the animal just arrives at a station
dispSum %>% filter(Consecutive.Dispersal > 0) %>% View
VTrack has some more analysis functions like creating activity space models.
GLATOS also includes tools for planning receiver arrays, simulating fish moving in an array, and some nice visualizations (which we will cover in the next episode).
Key Points
Basic Visualization and Plotting
Overview
Teaching: 30 min
Exercises: 0 minQuestions
How can I use GLATOS to plot my data?
What kinds of plots can I make with my data?
Objectives
We can use GLATOS to quickly and effectively visualize our data, now that we’ve cleaned it up.
One of the simplest ways is to use an abacus plot to display animal detections against the appropriate stations.
# Visualizing Data - Abacus Plots ####
# ?glatos::abacus_plot
# customizable version of the standard VUE-derived abacus plots
abacus_plot(detections_w_events,
location_col='station',
main='Walleye Detection by Station') # can use plot() variables here, they get passed thru to plot()
abacus_plot(detections_w_events,
location_col='glatos_array',
main='Walleye Detection by Array')
This is good, but cluttered. We can also filter out a single animal ID and plot only the abacus plot for that.
# pick a single fish to plot
# pick a single fish to plot
abacus_plot(detections_filtered[detections_filtered$animal_id== "22",],
location_col='station',
main="Animal 22 Detections By Station")
If we want to see actual physical distribution, a bubble plot will serve us better.
The glatos package provides a raster of the Great Lakes to the bubble plot, we will just use that.
# Bubble Plots for Spatial Distribution of Fish ####
# bubble variable gets the summary data that was created to make the plot
detections_filtered
?detection_bubble_plot
bubble_station <- detection_bubble_plot(detections_filtered,
location_col = 'station',
out_file = 'walleye_bubbles_by_stations.png')
bubble_station
bubble_array <- detection_bubble_plot(detections_filtered,
out_file = 'walleye_bubbles_by_array.png')
bubble_array
Glatos Challenge
Create a bubble plot of the station in Lake Erie only. Set the bounding box using the provided nw + se cordinates and resize the points. As a bonus, add points for the other receivers in Lake Erie. Hint:
?detection_bubble_plotwill help a lot. Here’s some code to get you started:erie_arrays <-c("DRF", "DRL", "DRU", "MAU", "RAR", "SCL", "SCM", "TSR") nw <- c(43, -83.75) se <- c(41.25, -82)Solution
erie_arrays <-c("DRF", "DRL", "DRU", "MAU", "RAR", "SCL", "SCM", "TSR") # Given nw <- c(43, -83.75) # Given se <- c(41.25, -82) # Given erie_detections <- detections_filtered %>% filter(glatos_array %in% erie_arrays) erie_rcvrs <- receivers %>% filter(glatos_array %in% erie_arrays) # For bonus erie_bubble <- detection_bubble_plot(erie_detections, receiver_locs = erie_rcvrs, # For bonus location_col = 'station', background_ylim = c(se[1], nw[1]), background_xlim = c(nw[2], se[2]), symbol_radius = 0.75, out_file = 'erie_bubbles_by_stations.png')
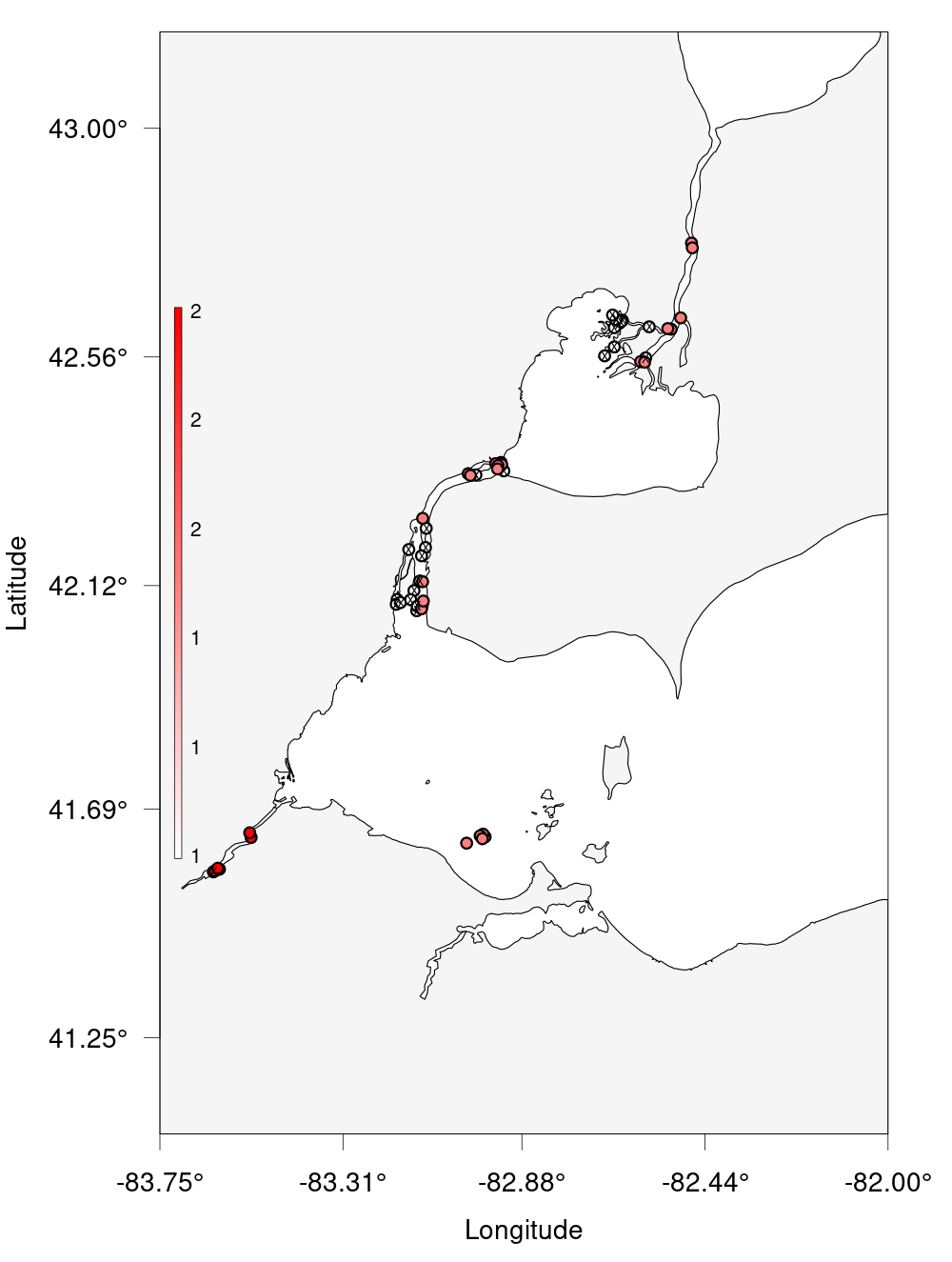
Key Points
Introduction to GLATOS and Spatial Mapping
Overview
Teaching: 30 min
Exercises: 0 minQuestions
Objectives
Spatial Data
We can use GLATOS to make a variety of useful maps by combining our GLATOS data with another library, sp (spatial). This requires us to manipulate the data in some new ways, but gives us more options when it comes to plotting our data.
First, we need to translate our GLATOS data into a spatially-aware dataframe. The sp library has some methods that can help us do this. However, we unfortunately can’t run them directly on the GLATOS dataframe. GLATOS stores data as a “glatos_detections” class (you can see this by running class(your-detections-dataframe)), and though it extends data.frame, some R methods do not operate on this object. However, we can get around this with some straightforward object type casting.
First, we start by importing the libraries we will need to use.
library(glatos) # Our main GLATOS library.
library(mapview) # We'll use this for slippy map plotting
library(sp) # Our spatial library
library(spdplyr) # A version of dplyr that allows us to work with spatial data
library(lubridate) # For manipulating dates later
Now we’ll pull in our data. For the purposes of this workshop, we’ll use the walleye test data included with GLATOS.
det_file <- system.file("extdata", "walleye_detections.csv", package = "glatos")
detections <- read_glatos_detections(det_file=det_file)
#Print the first few rows to check that it came in alright.
head(detections)
This should give us a glatos_detections dataframe including all our walleye data. To start the process of making a spatial object, we’re going to extract the latitude and longitude columns using the ‘select’ function we’ve already covered.
lat_long <- detections %>% select(deploy_long, deploy_lat)
lat_long
Make sure to select the columns in the order longitude, latitude. This is how many functions expect to receive the data and it can cause problems if you order them in the opposite direction.
Now that we have an object containing just the latitude and longitude, we can use our Spatial library to convert these to a spatially-aware object.
transformed_latLong <- SpatialPoints(as.data.frame(lat_long), CRS("+init=epsg:4326"))
#We cast lat_long to a dataframe because it is still a glatos_detections dataframe.
#CRS is our coordinate reference system.
transformed_latLong
This gives us a spatially aware set of latitudes and longitudes that we can now attach to our original dataframe. We can do this with the SpatialPointsDataFrame method, which takes coordinates and a dataframe and returns a SpatialPointsDataFrame object.
spdf <- SpatialPointsDataFrame(transformed_latLong, as.data.frame(detections))
#Once again we're casting detections directly to a standard dataframe.
spdf
The variable spdf now contains spatial data as well as all of the data we originally had. This lets us plot it without any further manipulation using the mapview function from the library of the same name.
mapview(spdf)
This will open in a browser window, and will give you a slippy map that lets you very quickly visualize your data in an interactive setting. If, however, you want to plot it in the default way to take advantage of the options there, that works too- the ‘points’ function will accept our spatially aware dataframe.
plot(greatLakesPoly, col = "grey")
#greatLakesPoly is a shapefile included with the glatos library that outlines the Great Lakes.
points(deploy_lat ~ deploy_long, data = spdf, pch = 20, col = "red",
xlim = c(-66, -62))
We can also use the spdplyr library to subset and slice our spatially-aware dataset, allowing us to pass only a subset- say, of a single animal- to mapview (or alternative plotting options).
mapview(spdf %>% filter(animal_id == 153)) #Plot only the points that correspond to the fish with the animal_id 153.
We could also subset along time, returning to the lubridate function we’ve already covered.
mapview(spdf %>% mutate(detection_timestamp_utc = ymd_hms(detection_timestamp_utc)) %>%
filter(detection_timestamp_utc > as.POSIXct("2012-05-01") & detection_timestamp_utc < as.POSIXct("2012-06-01")))
All of these options let us map and plot our data in a spatially-aware way.
If you want to investigate these options further, mapview and spdplyr are both extensively documented, allowing you to fine-tune your plots to suit your needs. Mapview’s documentation is available at this page, and links to additional spdplyr references can be found at its CRAN page.
Key Points
Introduction to actel
Overview
Teaching: 45 min
Exercises: 0 minQuestions
Objectives
actel is designed for studies where animals tagged with acoustic tags are expected to move through receiver arrays. actel combines the advantages of automatic sorting and checking of animal movements with the possibility for user intervention on tags that deviate from expected behaviour. The three analysis functions: explore, migration and residency, allow the users to analyse their data in a systematic way, making it easy to compare results from different studies.
Author: Dr. Hugo Flavio, ( hflavio@wlu.ca )
Supplemental Links and Related Materials:
Actel - a package for the analysis of acoustic telemetry data
The R package actel seeks to be a one-stop package that guides the user through the compilation and cleaning of their telemetry data, the description of their study system, and the production of many reports and analyses that are generally applicable to closed-system telemetry projects. actel tracks receiver deployments, tag releases, and detection data, as well as an additional concept of receiver groups and a network of the interconnectivity between them within our study area, and uses all of this information to raise warnings and potential oddities in the detection data to the user.
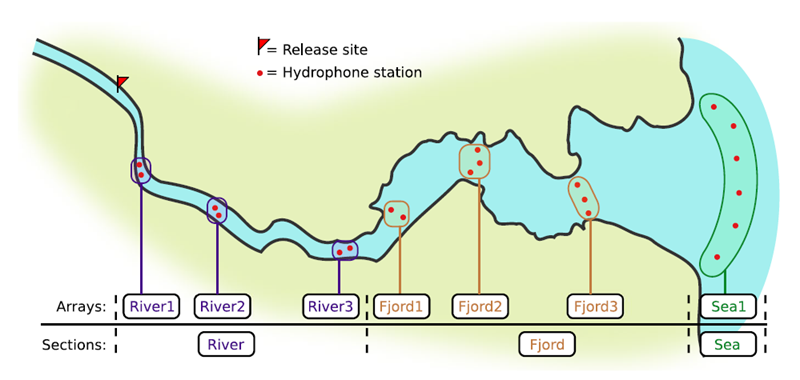

If you’re working in river systems, you’ve probably got a sense of which receivers form arrays. There is a larger-order grouping you can make called ‘sections’, and this will be something we can inter-compare our results with.
Preparing to use actel
With our receiver, tag, and detection data mapped to actel’s formats, and after creating our receiver groups and graphing out how detected animals may move between them, we can leverage actel’s analyses for our own datasets. Thanks to some efforts on the part of Hugo and of the glatos development team, we can move fairly easily with our glatos data into actel.
actel’s standard suite of analyses are grouped into three main functions - explore(), migration(), and residency(). As we will see in this and the next modules, these functions specialize in terms of their outputs but accept the same input data and arguments.
The first thing we will do is use actel’s built-in dataset to ensure we’ve got a working environment, and also to see what sorts of default analysis output Actel can give us.
Exploring
library("actel")
# The first thing you want to do when you try out a package is...
# explore the documentation!
# See the package level documentation:
?actel
# See the manual:
browseVignettes("actel")
# Get the citation for actel, and access the paper:
citation("actel")
# Finally, every function in actel contains detailed documentation
# of the function's purpose and parameters. You can access this
# documentation by typing a question mark before the function name.
# e.g.: ?explore
Working with actel’s example dataset
# Start by checking where your working directory is (it is always good to know this)
getwd()
# We will then deploy actel's example files into a new folder, called "actel_example".
# exampleWorkspace() will provide you with some information about how to run the example analysis.
exampleWorkspace("actel_example")
# Side note: When preparing your own data, you can create the initial template files
# with the function createWorkspace("directory_name")
# Take a minute to explore this folder's contents.
# -----------------------
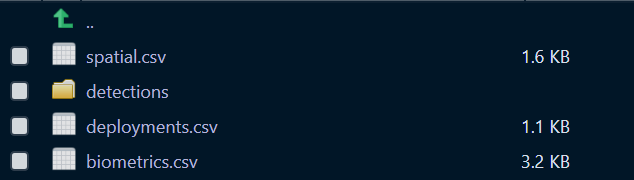
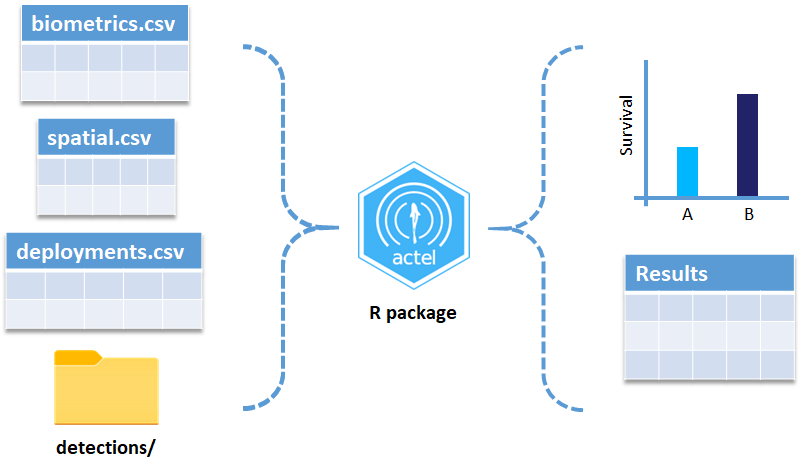
These are the files the Actel package depends on to create its output plots and result summary files.
biometrics.csv contains the detailed information on your tagged animals, where they were released and when, what the tag code is for that animal, and a grouping variable for you to set. Additional columns can be part of biometrics.csv but these are the minimum requirements. The names of our release sites must match up to a place in our spatial.csv file, where you release the animal has a bearing on how it will begin to interact with your study area.

deployments.csv concerns your receiver deployments, when and where each receiver by serial number was deployed. Here again you can have more than the required columns but you have to have a column that corresponds to the station’s ‘name’, which will have a paired entry in the spatial.csv file as well, and a start and end time for the deployment.

Finally, we have to have some number of detection files. This is helpfully a folder to make it easier on folks who don’t have aggregators like GLATOS and OTN to pull together all the detection information for their tags. While we could drop our detection data in here, when the time comes to use GLATOS data with actel we’ll see how we can create these data structures straight from the glatos data objects. Here also Hugo likes to warn people about opening their detection data files in Excel directly… Excel’s eaten a few date fields on all of us, I’m sure. We don’t have a hate-on for Excel or anything, like our beloved household pet, we’ve just had to learn there are certain places we just can’t bring it with us.
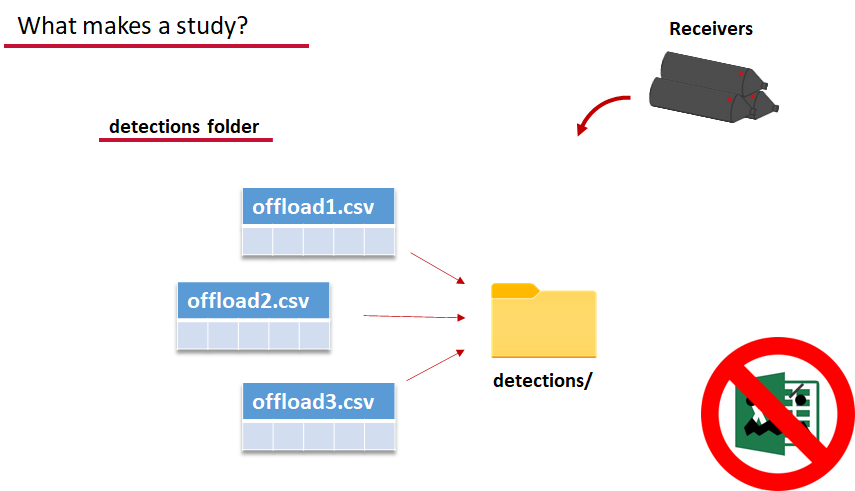
OK, now we have a biometrics file of our tag releases with names for each place we released our tags in spatial.csv, we have a deployments file of all our receiver deployments and the matching names in spatial.csv, and we’ve got our detections. These are the minimum components necessary for actel to go to work.
# move into the newly created folder
setwd('actel_example')
# Run analysis. Note: This will open an analysis report on your web browser.
exp.results <- explore(tz = 'US/Central', report = TRUE)
# Because this is an example dataset, this analysis will run very smoothly.
# Real data is not always this nice to us!
# ----------
# If your analysis failed while compiling the report, you can load
# the saved results back in using the dataToList() function:
exp.results <- dataToList("actel_explore_results.RData")
# If your analysis failed before you had a chance to save the results,
# load the pre-compiled results, so you can keep up with the workshop.
# Remember to change the path so R can find the RData file.
exp.results <- dataToList("pre-compiled_results.RData")
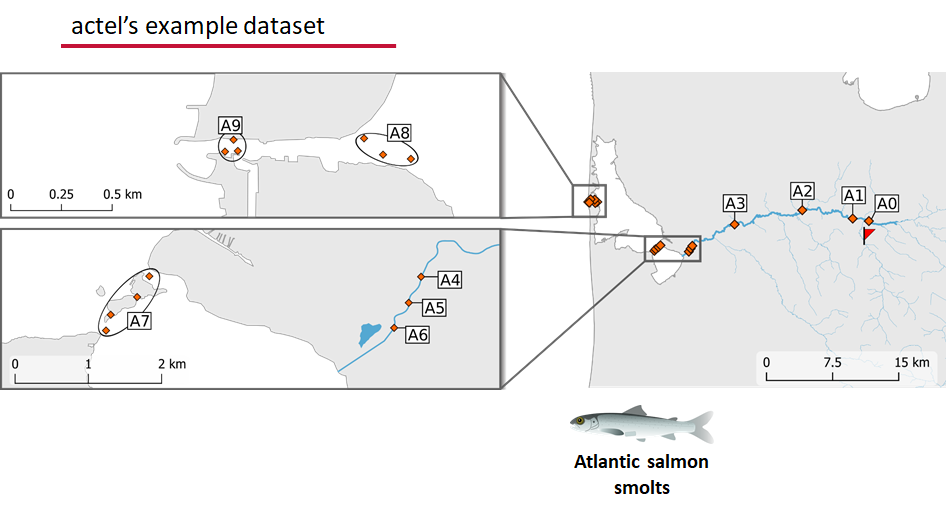
This example dataset is a salmon project working in a river-and-estuary system in northeastern Denmark. There are lots of clear logical separations in the array design and the general geography here that we will want to compare and deal with separately.
Exploring the output of explore()
# What is inside the output?
names(exp.results)
# What is inside the valid movements?
names(exp.results$valid.movements)
# let's have a look at the first one:
exp.results$valid.movements[["R64K-4451"]]
# and here are the respective valid detections:
exp.results$valid.detections[["R64K-4451"]]
# We can use these results to obtain our own plots (We will go into that later)
These files are the minimum requirements for the main analyses, but there are more files we can create that will give us more control over how actel sees our study area.
A good deal of checking occurs when you first run any analysis function against your data files, and actel is designed to step through any problems interactively with you and prompt you for the preferred resolutions. These interactions can be saved as plaintext in your R script if you want to remember your choices, or you can optionally clean up the input files directly and re-run the analysis function.
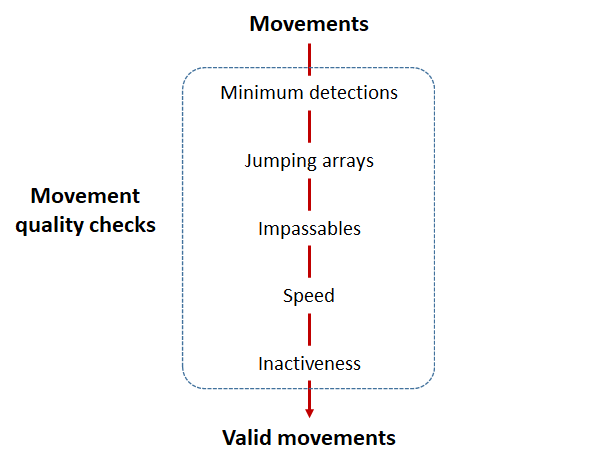
Checks that actel runs:
Actel will calculate the movement path for each individual animal, and determine whether that animal has met a threshhold for minimum detections and detection events, whether it snuck across arrays that should have detected it but didn’t, whether it reached unlikely speeds or crossed impassable areas
Minimum detections:
Controlled by the minimum.detections and max.interval arguments, if a tag has only 1 movement with less than n detections, discard the tag. Note that animals with movement events > 1 will pass this filter regardless of n.
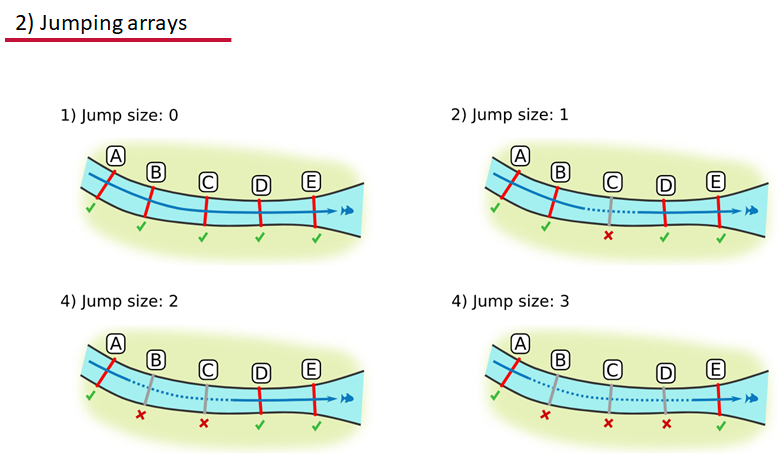
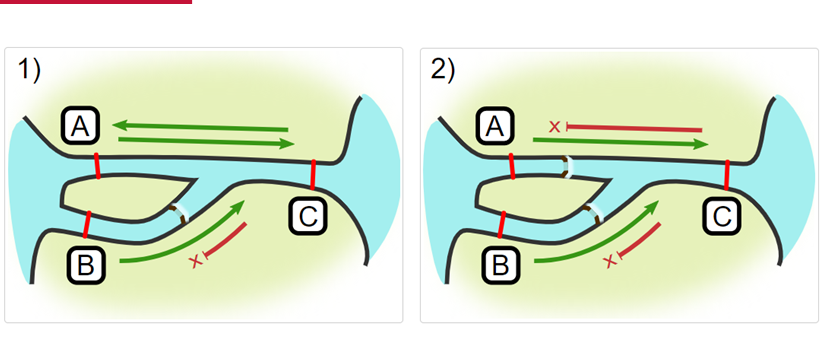
Jumping arrays:
In cases where you have gates of arrays designed to capture all movement up and down a linear system, you may want to verify that your tags have not ‘jumped’ past one or more arrays before being re-detected. You can use the jump.warning and jump.error arguments to explore() to set the number of acceptable jumps across your array system are permissible.
Impassables:
When we define how our areas are connected in the spatial.txt file, it tells actel which movements are -not- permitted explicitly, and can tell us about when those movements occur. This way, we can account for manmade obstacles or make other assumptions about one-way movement and verify our data against them.
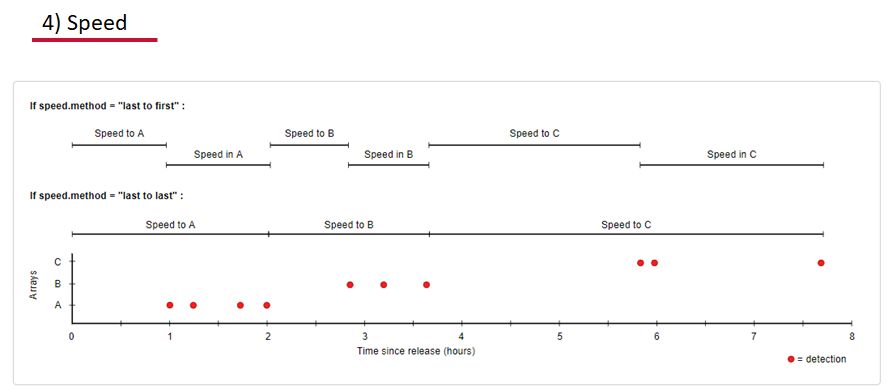
Speed:
actel can calculate the minimum speed of an animal between (and optionally within) detection events using the distances calculated from spatial.csv into a new distance matrix file, distances.csv, and we can supply speed.warning, speed.error, and speed.method to tailor our report to the speed and calculation method we want to submit our data to.
Inactivity:
With the inactive.warning and inactive.error arguments, we can flag entries that have spent a longer time than expected not transiting between locations.
Creating a spatial.txt file
Your study area might be simple and linear, may be complicated and open, completely interconnected. It is more likely a combination of the two! We can use DOT notation (commonly used in graphing applications like GraphViz and Gephi) to create a graph of our areas and how they are allowed to inter-mingle. actel can read this information as DOT notation using readDOT() or you can provide a spatial.txt with the DOT information already inline.
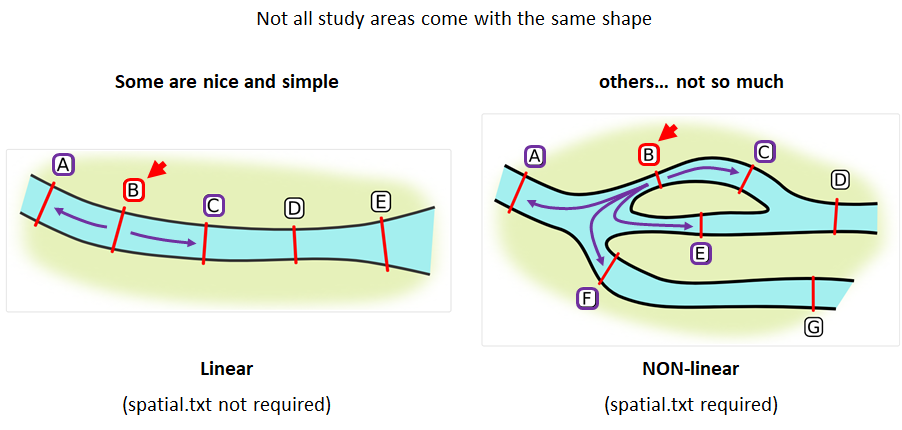
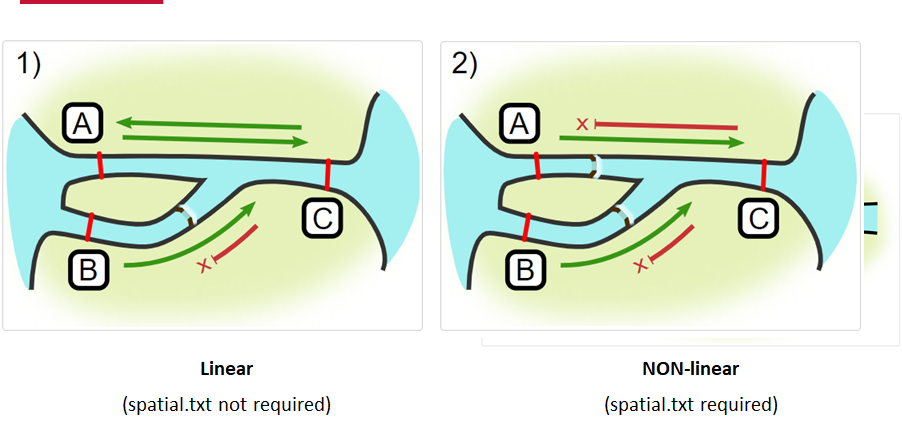
The question you must ask when creating spatial.txt files is: for each location, where could my animal move to and be detected next?
The DOT for the simple system on the left is:
A -- B -- C -- D -- E
And for the more complicated system on the right it’s
A -- B -- C -- D
A -- E -- D
A -- F -- G
B -- E -- F
B -- F
C -- E
Challenge : DOT notation
Using the DOT notation tutorial linked here, discover the notation for a one-way connection and write the DOT notations for the systems shown here:
Solution:
Left-hand diagram:
A -- B A -- C B -> CRight-hand diagram:
A -- B A -> C B -> C
Generating an initial distance matrix file
A distance matrix tracks the distance between each pair of spatial data points in a dataframe. In actel, our dataframe is spatial.csv, and we can use this datafile as well as a shapefile describing our body or bodies of water, with the functions loadShape(), transitionLayer() and distancesMatrix() to generate a distance matrix for our study area.
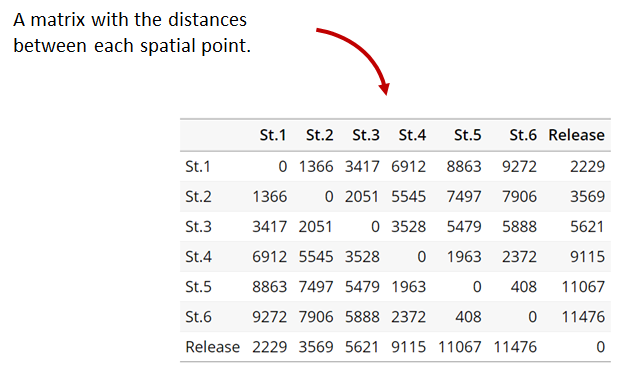
Let’s use actel’s built-in functions to create a distance matrix file. The process generally will be:
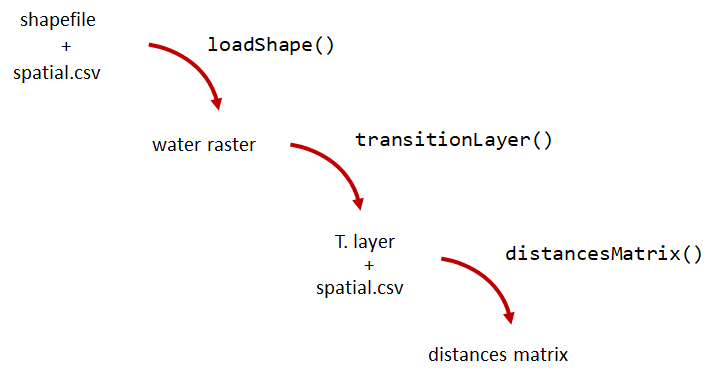
# Let's load the spatial file individually, so we can have a look at it.
spatial <- loadSpatial()
head(spatial)
# When doing the following steps, it is imperative that the coordinate reference
# system (CRS) of the shapefile and of the points in the spatial file are the same.
# In this case, the values in columns "x" and "y" are already in the right CRS.
# loadShape will rasterize the input shape, using the "size" argument as a reference
# for the pixel size. Note: The units of the "size" will be the same as the units
# of the shapefile projection (i.e. metres for metric projections, and degrees for latlong systems)
#
# In this case, we are using a metric system, so we are saying that we want the pixel
# size to be 10 metres.
#
# NOTE: Change the 'path' to the folder where you have the shape file.
# ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
water <- loadShape(path = "replace/with/path/to/shapefile",
shape = "stora_shape_epsg32632.shp", size = 10,
coord.x = "x", coord.y = "y")
# The function above can run without the coord.x and coord.y arguments. However, by including them,
# you are allowing actel to load the spatial.csv file on the fly and check if the spatial points
# (i.e. hydrophone stations and release sites) are positioned in water. This is very important,
# as any point position on land will be cut off during distance calculations.
# Now we need to create a transition layer, which R will use to estimate the distances
tl <- transitionLayer(water)
# We are ready to try it out! distancesMatrix will automatically search for a "spatial.csv"
# file in the current directory, so remember to keep that file up to date!
dist.mat <- distancesMatrix(tl, coord.x = "x", coord.y = "y")
# have a look at it:
dist.mat
migration and residency
The migration() function runs the same checks as explore() and can be advantageous in cases where your animals can be assumed to be moving predictably.
The built-in vignettes (remember: browseVignettes("actel") for the interactive vignette) are the most comprehensive description of all that migration() offers over and above explore() but one good way might be to examine its output. For simple datasets and study areas like our example dataset, the arguments and extra spatial.txt and distances.csv aren’t necessary. Our mileage may vary.
# Let's go ahead and try running migration() on this dataset.
mig.results <- migration(tz = 'Europe/Copenhagen', report = TRUE)
the migration() function will ask us to invalidate some flagged data or leave it in the analysis, and then it will ask us to save a copy of the source data once we’ve cleared all the flags. Then we get to see the report. It will show us things like our study locations and their graph relationship:

… a breakdown of the biometrics variables it finds in biometrics.csv

… and a temporal analysis of when animals arrived at each of the array sections of the study area.
To save our choices in actel’s interactives, let’s include them as raw text in our R block. We’ll test this by calling residency() with a few pre-recorded choices, as below:
# Try copy-pasting the next five lines as a block and run it all at once.
res.results <- residency(tz = 'Europe/Copenhagen', report = TRUE)
comment
This is a lovely fish
n
y
# R will know to answer each of the questions that pop up during the analysis
# with the lines you copy-pasted together with your code!
# explore the reports to see what's new!
# Note: There is a known bug in residency() as of actel 1.2.0, which for some datasets
# will cause a crash with the following error message:
#
# Error in tableInteraction(moves = secmoves, tag = tag, trigger = the.warning, :
# argument "save.tables.locally" is missing, with no default
#
# This has already been corrected and a fix has been released in actel 1.2.1.
Further exploration of actel: Transforming the results
# Review more available features of Actel in the manual pages!
vignette("f-0_post_functions", "actel")
Key Points
Preparing FACT/OTN/GLATOS Data for actel
Overview
Teaching: 45 min
Exercises: 0 minQuestions
How do I take my
glatosdata and format for actel?Objectives
Preparing our data to use in Actel
So now, as the last piece of stock curriculum for this workshop, let’s quickly look at how we can take the data reports we get from GLATOS (or any other OTN-compatible data partner, like FACT, ACT, or OTN proper) and make it ready for Actel.
# Using GLATOS-style data in Actel ####
# install.packages('actel') # CRAN Version 1.2.1
# Or the development version:
# remotes::install_github("hugomflavio/actel", build_opts = c("--no-resave-data", "--no-manual"), build_vignettes = TRUE)
library(actel)
library(stringr)
library(glatos)
library(tidyverse)
Within actel there is a preload() function for folks who are holding their deployment, tagging, and detection data in R variables already instead of the files and folders we saw in the actel intro. This function expects 4 input objects, plus the ‘spatial’ data object that will help us describe the locations of our receivers and how the animals are allowed to move between them.
To achieve the minimum required data for actel’s ingestion, we’ll want deployment and recovery datetimes, instrument models, etc. We can transform our metadata’s standard format into the standard format and naming schemes expected by actel::preload() with a bit of dplyr magic:
# Load the GLATOS workbook and detections -------------
wb_file <-system.file("extdata", "walleye_workbook.xlsm", package="glatos")
wb_metadata <- glatos::read_glatos_workbook(wb_file)
# Our project's detections file - I'll use our walleye detections
det_file <- system.file("extdata", "walleye_detections.csv", package = "glatos")
detections <- read_glatos_detections(det_file)
# Let's say we didn't have tag metadata for the walleye.
# Here's a way to reverse-engineer it from the walleye detections
# Don't try this at home, just use the workbook reader
tags <- detections %>%
dplyr::group_by('animal_id') %>%
dplyr::select('animal_id', 'transmitter_codespace',
'transmitter_id', 'tag_type', 'tag_serial_number',
'common_name_e', 'capture_location', 'length',
'weight', 'sex', 'release_group', 'release_location',
'release_latitude', 'release_longitude',
'utc_release_date_time', 'glatos_project_transmitter',
'glatos_tag_recovered', 'glatos_caught_date') %>%
unique()
# So now this is our animal tagging metadata
wb_metadata$animals
# and this is our receiver deployment metadata
wb_metadata$receivers
# but our detections are still in this separate spot
det_file <- system.file("extdata", "walleye_detections.csv", package = "glatos")
detections <- read_glatos_detections(det_file)
# Mutate metadata into Actel format ----
# Create a station entry from the glatos array and station number.
# --- add station to receiver metadata ----
full_receiver_meta <- wb_metadata$receivers %>%
dplyr::mutate(
station = paste(glatos_array, station_no, sep = '')
)
We’ve now imported our data, and renamed a few columns from the receiver metadata sheet so that they are in a nicer format. We also create a ‘station’ column that is of the form array_code + station_name, guaranteed unique for any project across the entire Network.
Formatting - Tagging and Deployment Data
As we saw earlier, tagging metadata is entered into Actel as biometrics, and deployment metadata as deployments. These data structures also require a few specially named columns, and a properly formatted date.
# All dates will be supplied to Actel in this format:
actel_datefmt = '%Y-%m-%d %H:%M:%S'
# biometrics is the tag metadata. If you have a tag metadata sheet, it looks like this:
actel_biometrics <- wb_metadata$animals %>% dplyr::mutate(Release.date = format(utc_release_date_time, actel_datefmt),
Signal=as.integer(tag_id_code),
Release.site = release_location) %>%
# subset these tag releases to the animals we actually have
# detections for in our demo dataset
# Only doing this because the demo dataset is so cut-down, wouldn't make sense
# to have 500 tags and only 3 of them with detections.
dplyr::filter(animal_id %in% tags$animal_id)
# Actel Deployments ----
# deployments is based in the receiver deployment metadata sheet
actel_deployments <- full_receiver_meta %>% dplyr::filter(!is.na(recover_date_time)) %>%
mutate(Station.name = station,
Start = format(deploy_date_time, actel_datefmt), # no time data for these deployments
Stop = format(recover_date_time, actel_datefmt), # not uncommon for this region
Receiver = ins_serial_no) %>%
arrange(Receiver, Start)
Detections
For detections, a few columns need to exist: Transmitter holds the full transmitter ID. Receiver holds the receiver serial number, Timestamp has the detection times, and we use a couple of Actel functions to split CodeSpace and Signal from the full transmitter_id.
# Renaming some columns in the Detection extract files
actel_dets <- detections %>% dplyr::mutate(Transmitter = transmitter_id,
Receiver = as.integer(receiver_sn),
Timestamp = format(detection_timestamp_utc, actel_datefmt),
CodeSpace = extractCodeSpaces(transmitter_id),
Signal = extractSignals(transmitter_id))
Creating the Spatial dataframe
The spatial dataframe must have entries for all release locations and all receiver deployment locations. Basically, it must have an entry for every distinct location we can say we know an animal has been.
# Prepare and style entries for receivers
# Prepare and style entries for receivers
actel_receivers <- full_receiver_meta %>% dplyr::mutate( Station.name = station,
Latitude = deploy_lat,
Longitude = deploy_long,
Type='Hydrophone') %>%
dplyr::mutate(Array=glatos_array) %>% # Having this many distinct arrays breaks things with few clues as to why.
dplyr::select(Station.name, Latitude, Longitude, Array, Type) %>%
distinct(Station.name, Latitude, Longitude, Array, Type)
# Actel Tag Releases ---------------
# Prepare and style entries for tag releases
actel_tag_releases <- wb_metadata$animals %>% mutate(Station.name = release_location,
Latitude = release_latitude,
Longitude = release_longitude,
Type='Release') %>%
mutate(Array = case_when(Station.name == 'Maumee' ~ 'SIC',
Station.name == 'Tittabawassee' ~ 'TTB',
Station.name == 'AuGres' ~ 'AGR')) %>% # This value needs to be the nearest array to the release site
distinct(Station.name, Latitude, Longitude, Array, Type)
# Combine Releases and Receivers ------
# Bind the releases and the deployments together for the unique set of spatial locations
actel_spatial <- actel_receivers %>% bind_rows(actel_tag_releases)
Now, for longer data series, we may have similar stations that were deployed and redeployed at very slightly different locations. One way to deal with this issue is that for stations that are named the same, we assign an average location in spatial.
Another way we might overcome this issue could be to increment station_names that are repeated and provide their distinct locations.
# group by station name and take the mean lat and lon of each station deployment history.
actel_spatial_sum <- actel_spatial %>% dplyr::group_by(Station.name, Type) %>%
dplyr::summarize(Latitude = mean(Latitude),
Longitude = mean(Longitude),
Array = first(Array))
Creating the Actel data object w/ preload()
Now you have everything you need to call preload().
# Specify the timezone that your timestamps are in.
# OTN provides them in UTC/GMT.
# FACT has both UTC/GMT and Eastern
# GLATOS provides them in UTC/GMT
# If you got the detections from someone else,
# they will have to tell you what TZ they're in!
# and you will have to convert them before importing to Actel!
tz <- "GMT0"
# You've collected every piece of data and metadata and formatted it properly.
# Now you can create the Actel project object.
actel_project <- preload(biometrics = actel_biometrics,
spatial = actel_spatial_sum,
deployments = actel_deployments,
detections = actel_dets,
tz = tz)
There will very likely be some issues with the data that the Actel checkers find and warn us about. Detections outside the deployment time bounds, receivers that aren’t in your metadata. For the purposes of today, we will drop those rows from the final copy of the data, but you can take these prompts as cues to verify your input metadata is accurate and complete. It is up to you in the end to determine whether there is a problem with the data, or an overzealous check that you can safely ignore. Here our demo is using a very deeply subsetted version of one project’s data, and it’s not surprising to be missing some deployments.
Once you have an Actel object, you can run explore() to generate your project’s summary reports:
# Get summary reports from our dataset:
actel_explore_output <- explore(datapack=actel_project,
report=TRUE,
print.releases=FALSE)
Review the file that Actel pops up in our browser. It presumed our Arrays were arranged linearly and alphabetically, which is of course not correct! We’ll have to tell Actel how our arrays are inter-connected. To do this, we’ll need to design a spatial.txt file for our detection data.
To help with this, we can go back and visualize our study area interactively, and start to see how the Arrays are connected.
# Designing a spatial.txt file -----
library(mapview)
library(spdplyr)
library(leaflet)
library(leafpop)
## Exploration - Let's use mapview, since we're going to want to move around,
# drill in and look at our stations
# Get a list of spatial objects to plot from actel_spatial_sum:
our_receivers <- as.data.frame(actel_spatial_sum) %>%
dplyr::filter(Array %in% (actel_spatial_sum %>% # only look at the arrays already in our spatial file
distinct(Array))$Array)
# and plot it using mapview. The popupTable() function lets us customize our tooltip
mapview(our_receivers %>%
select(Longitude, Latitude) %>% # and get a SpatialPoints object to pass to mapview
SpatialPoints(CRS('+proj=longlat')),
popup = popupTable(our_receivers,
zcol = c("Array",
"Station.name"))) # and make a tooltip we can explore
Can we design a graph and write it into spatial.txt that fits all these Arrays together? The glatos_array value we put in Array looks to be a bit too granular for our purposes. Maybe we can combine many arrays that are co-located in open water into a Lake Huron ‘zone’, preserving the complexity of the river systems but creating one basin to which we can connect.
To do this, we only need to update the arrays in our spatial.csv file or spatial dataframe.
# We only need to do this in our spatial.csv file!
huron_arrays <- c('WHT', 'OSC', 'STG', 'PRS', 'FMP',
'ORM', 'BMR', 'BBI', 'RND', 'IGN',
'MIS', 'TBA')
# Update actel_spatial_sum to reflect the inter-connectivity of the Huron arrays.
actel_spatial_sum_lakes <- actel_spatial_sum %>%
dplyr::mutate(Array = if_else(Array %in% huron_arrays, 'Huron', #if any of the above, make it 'Huron'
Array)) # else leave it as its current value
# Notice we haven't changed any of our data or metadata, just the spatial table
The spatial.txt file I created is in the data subfolder of the workshop materials, we can use it to define the connectivity between our arrays and the Huron basin.
spatial_txt_dot = '../../../data/glatos_spatial.txt' # relative path to this workshop's folder
# How many unique spatial Arrays do we still have, now that we've combined
# so many into Huron?
actel_spatial_sum_lakes %>% dplyr::group_by(Array) %>% dplyr::select(Array) %>% unique()
# OK. let's analyze this dataset with our reduced spatial complexity
actel_project <- preload(biometrics = actel_biometrics,
spatial = actel_spatial_sum_lakes,
deployments = actel_deployments,
detections = actel_dets,
dot = readLines(spatial_txt_dot),
tz = tz)
now actel understands the connectivity between our arrays better!
actel_explore_output_lakes <- explore(datapack=actel_project,
report=TRUE,
print.releases=FALSE)
# We no longer get the error about movements skipping/jumping across arrays!
Key Points
Other OTN Telemetry Curriculums
Overview
Teaching: 0 min
Exercises: 0 minQuestions
How can I keep expanding my learning?
Objectives
OTN has hosted other workshops in the past which contain different code sets that may be useful to explore after this workshop.
-
IdeasOTN Telemetry Workshop Series 2020: code available here and videos available on our YouTube here
-
SPG workshop 2020. Videos will soon be posted on our YouTube.
Many of our Intro to R workshops are based upon this curriculum from The Carpentries
Key Points